Dr. Partha Majumder is a Gen-AI product engineer and research scientist with a Ph.D. from IIT Bombay. He specializes in building end-to-end, production-ready Gen-AI applications using Python, FastAPI, LangChain/LangGraph, and Next.js.
Core stack
Python, FastAPI, LangChain/LangGraph, Next.js
Applied Gen-AI
AI video, avatar videos, real-time streaming, voice agents
This part focuses on memory—because performance work in CUDA often becomes memory work. A kernel can have plenty of arithmetic, but it will still run slow if threads wait on memory too often.
In this chapter, the goal is to build an intuitive map of the CUDA memory hierarchy (registers, shared, local, constant, texture, global) and then zoom in on global memory—the largest and most common storage space used for GPU datasets.
Efficient memory handling is a crucial aspect of all programming languages. In high-performance computing , memory management plays very significant role. Many tasks depend on the speed at which data can be loaded and stored. Having abundant low-latency, high-bandwidth memory can significantly boost performance. However, acquiring large, high-performance memory isn’t always feasible or cost-effective.
In such situations, the memory model becomes crucial. It allows you to fine-tune the balance between latency and bandwidth, customizing data placement according to the hardware memory subsystem. CUDA’s memory model accomplishes this seamlessly by harmonizing host and device memory systems, granting you full access to the memory hierarchy. This explicit control over data placement optimizes performance without the need for extravagant memory resources.
Principle Of Locality
Applications do not access arbitrary data or execute arbitrary code at any point in time. Instead, applications often follow the principle of locality, which suggests that they access a relatively small and localized portion of their address space at any point in time. This principle is categorized into two primary types of locality:
Spatial Locality: This principle indicates that if a program accesses a particular memory location, it’s likely to access nearby memory locations soon afterward. This is a result of data structures or loops that group related data together in memory. When threads cooperate and access adjacent memory, spatial locality is enhanced, resulting in efficient memory access.
Temporal Locality: Temporal locality suggests that if a program accesses a memory location, it’s likely to access the same location in the near future. This is common in loops and recurring operations where the same data is accessed repeatedly. Caches and shared memory are essential in exploiting temporal locality, reducing the need to access slower global memory.
Memory Hierarchy
The memory hierarchy is a fundamental framework that governs how the GPU manages data. This hierarchy relies on two types of memory: one with low latency and limited storage capacity, used for actively processed data, and another with high latency and ample storage capacity, reserved for future tasks. A strong grasp of this hierarchy is essential for unlocking the full computational potential of GPUs.
To boost performance, modern computer systems employ a memory hierarchy concept. This concept encompasses multiple memory levels, each offering different data access speeds. However, quicker access on some levels often comes at the expense of reduced storage space. The reason this hierarchy matters lies in the principle of locality, leading to the incorporation of various memory levels, each with its distinctive attributes, such as access speed, data transfer capabilities, and storage capacity.
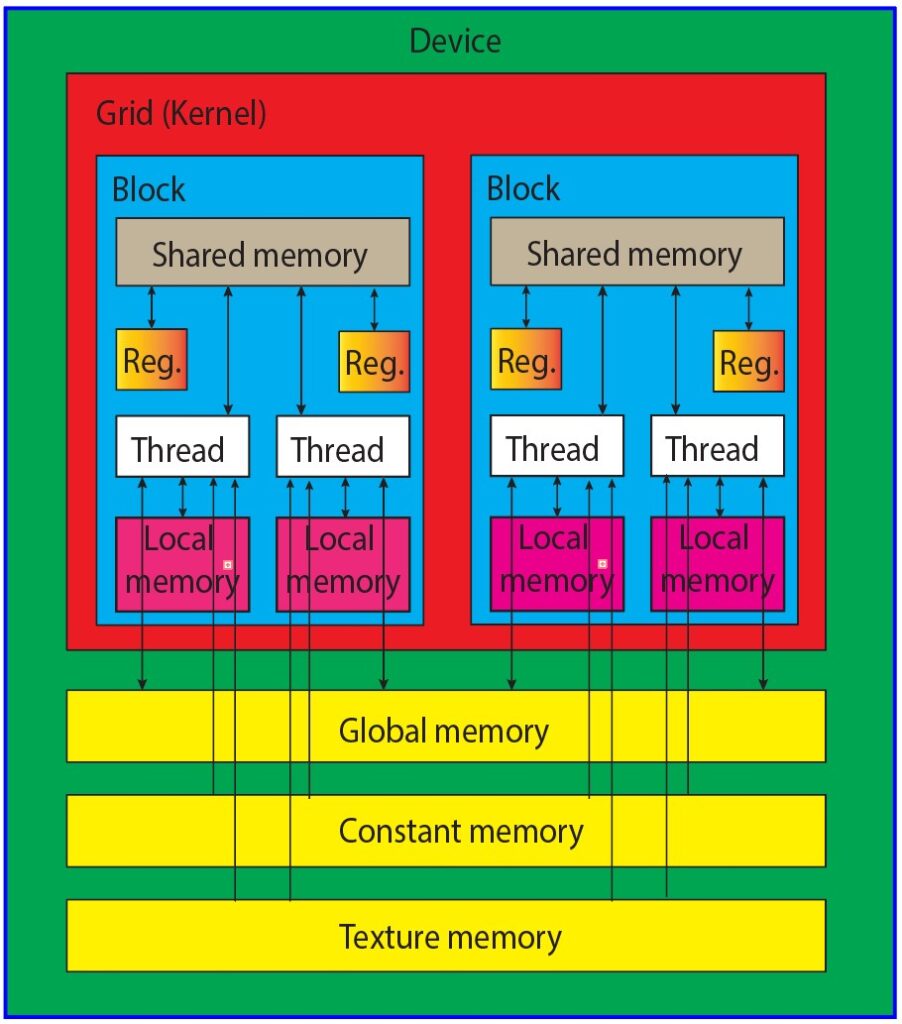
The CUDA memory model provides access to several programmable memory types, including registers, shared memory, local memory, constant memory, texture memory, and global memory. The figure below (see Figure 1) shows where these memory spaces sit in the hierarchy, along with their scope, lifetime, and caching behavior.
Every thread within a kernel has its own private local memory, while a thread block has its own shared memory, visible to all threads in that block and persisting for the duration of the block’s execution. Global memory is accessible to all threads, and there are two read-only memory spaces available to all threads: constant and texture memory. Global, constant, and texture memory spaces are each optimized for distinct purposes. Texture memory offers diverse address modes and filtering options for various data layouts, and the contents of global, constant, and texture memory have the same lifespan as the application. Let us discuss each memory types one by one.
Fig. 1. CUDA memory model hierarchy showing different memory types and their characteristics
Registers: Registers represent the fastest form of memory available on a GPU. Any automatic variable declared within a kernel without additional type qualifiers is typically stored in a register. In certain cases, arrays declared in a kernel can also be allocated to registers, but this only occurs when the array indices are constant and can be determined at compile time. These register variables are private to each individual thread and are primarily used to store frequently accessed thread-private data within a kernel. It’s important to note that the lifetime of register variables is limited to the duration of the kernel’s execution. Once a kernel completes its execution, any register variable becomes inaccessible. Registers are a finite and valuable resource allocated among active warps in a Streaming Multiprocessor (SM).
Local memory: Variables within a kernel that meet the criteria for registers but exceed the available register capacity are redirected to local memory. Variables that the compiler is inclined to allocate to local memory are local arrays accessed using indices with values that cannot be ascertained at compile-time, and large local structures or arrays that would overconsume the allocated register space, and any variable surpassing the kernel’s register limit. It is essential to recognize that the term “local memory” can be somewhat misleading. Values spilling into local memory physically reside in the same location as global memory. Accessing local memory involves high latency, low bandwidth, and is subject to the efficiency requirements for memory access patterns described later in this chapter.
Shared Memory: Shared memory lives on the GPU chip and offers much higher bandwidth and lower latency than local or global memory. It behaves somewhat like a programmable L1 cache. Each Streaming Multiprocessor (SM) has a limited shared-memory budget that is split across resident thread blocks—so using too much shared memory can reduce the number of active blocks/warps. Shared memory is declared inside a kernel and exists for the lifetime of a thread block. Once the block finishes, the shared memory is released and reused. Shared memory is declared using the shared keyword. For example:
__shared__ int sharedData[256];
Constant Memory: Constant memory is meant for read-only values such as constants and lookup tables. The first access is cached, so repeated reads become much faster—especially when many threads read the same value. Constant memory is limited in size, so it works best for small, frequently reused read-only data. Constant memory is declared using the constant keyword. For example:
__constant__ float myConstantValue;
Texture Memory: Texture memory is designed to optimize texture access for GPU applications, especially those related to graphics, image processing, and computer vision. It provides a convenient and efficient way to store and retrieve data, such as textures, that are frequently accessed during GPU computation. Texture memory is cached, which means that data is temporarily stored in a high-speed cache. Texture memory is primarily intended for storing read-only data, such as textures used in graphics applications. While you can read from texture memory, it’s not designed for direct writes or modifications.
Global Memory: Global memory is one of the primary memory spaces in a GPU, typically associated with the GPU’s DRAM (Dynamic Random-Access Memory). It is the largest memory space available in the GPU and is accessible to all threads running on the GPU. Global memory offers a substantial storage capacity, making it suitable for storing large datasets and variables. It is especially valuable when dealing with massive data arrays. Global memory is relatively slow when compared to other memory types. This is because it is physically located off-chip, which means that accessing data from global memory takes more time compared to on-chip memory like shared memory or registers. Data stored in global memory is accessible by any thread within any thread block. This allows them to be accessible from any function or kernel within your CUDA program. You can declare global memory statically or dynamically, depending on your program’s requirements.
The key characteristics of these memory spaces are also summarized in the table below.
Memory Type
On/Off Chip
Access
Scope
Lifetime
Cached
Registers
On-Chip
R/W
1 thread
Thread
No
Local Memory
Off-Chip
R/W
1 thread
Thread
No
Shared Memory
On-Chip
R/W
All threads in block
Block
No
Global Memory
Off-Chip
R/W
All threads + host
Host allocation
No
Constant Memory
Off-Chip
R
All threads + host
Host allocation
Yes
Texture Memory
Off-Chip
R
All threads + host
Host allocation
Yes
Table 1. Key characteristics of CUDA memory spaces (location, access, scope, lifetime, and caching).
Global Memory
Global memory is a fundamental component of memory management in CUDA programming. It plays a central role in enabling the parallel processing capabilities of GPUs (Graphics Processing Units) and is critical for harnessing the full computational power of these devices. In this detailed explanation, we will explore global memory, covering its characteristics, allocation, data transfer, synchronization, coalescence, and optimization.
Characteristics of Global Memory
Global memory in CUDA represents a large, off-chip memory space that is accessible by all threads in a GPU. It is the primary means of data sharing and communication between threads, and it exhibits several key characteristics:
Capacity: Global memory is the largest memory space in the GPU. It offers a substantial storage capacity, making it suitable for storing large datasets and variables required by parallel algorithms.
Latency: While global memory provides ample storage, it is relatively slow when compared to other memory types in the GPU memory hierarchy. This latency stems from the physical off-chip location of global memory.
Accessibility: Global memory is a universal memory space that can be accessed by any thread within any block. This accessibility makes it a primary choice for storing and sharing data across threads.
Persistence: Data stored in global memory persists across multiple kernel launches. It maintains its state throughout the entire program execution on the GPU, allowing data to be shared and used by different stages of the program.
Allocation and Deallocation
Allocating memory in global memory is the first step in utilizing this memory space effectively. Memory allocation in CUDA is achieved through the cudaMalloc() function, which reserves a specified amount of global memory to store data. To allocate global memory, you need to provide the size of the memory block you wish to allocate. The function returns a pointer to the allocated memory, which can be used to access and manipulate the data stored in global memory. Here’s an example of how to allocate memory in global memory:
int* deviceData; // Pointer to device (GPU) memory// Allocate memory on the GPUcudaMalloc((void**)&deviceData, sizeof(int) * dataSize);// Check for successful memory allocationif (deviceData == nullptr) { // Handle memory allocation failure}
In this example, cudaMalloc() is used to allocate an array of integers on the GPU. The size of the allocation is determined by sizeof(int) * dataSize, where dataSize represents the number of integers to be stored. It is also important to check for the success of memory allocation, as the allocation may fail if there is insufficient available global memory. A failure to allocate memory should be handled gracefully in your CUDA application.
Deallocating global memory is equally important to prevent memory leaks. The cudaFree() function is used to release the allocated memory when it is no longer needed.
cudaFree(deviceData); // Deallocate global memory
By deallocating memory, you ensure that resources are freed up for other parts of your program.
Data Transfer
Efficient data transfer between the CPU (host) and the GPU (device) is crucial for CUDA applications. Data often needs to be moved between these two entities for processing or to share results. CUDA provides functions like cudaMemcpy() for data transfer between host and device memory. There are several memory copy directions in CUDA:
cudaMemcpyHostToHost: Data transfer from host to host.
cudaMemcpyHostToDevice: Data transfer from host to device.
cudaMemcpyDeviceToHost: Data transfer from device to host.
cudaMemcpyDeviceToDevice: Data transfer from device to device.
Here’s an example of how to use cudaMemcpy() to transfer data from the host to the device:
int* hostArray; // Pointer to host (CPU) memoryint* deviceArray; // Pointer to device (GPU) memory// Allocate memory on the CPU and the GPUhostArray = (int*)malloc(sizeof(int) * arraySize);cudaMalloc((void**)&deviceArray, sizeof(int) * arraySize);// Copy data from the host to the devicecudaMemcpy(deviceArray, hostArray, sizeof(int) * arraySize, cudaMemcpyHostToDevice);
In this code snippet, data stored in hostArray on the CPU is copied to deviceArray on the GPU using cudaMemcpy(). The function handles the data transfer efficiently, ensuring that the data arrives correctly on the GPU. The direction of data transfer is specified as cudaMemcpyHostToDevice.
Efficient data transfer is vital for maintaining the overall performance of CUDA applications, particularly when handling large datasets. It’s important to manage data transfers carefully to minimize overhead and latency.
Synchronization
Synchronization in CUDA is essential for ensuring that data transfers and kernel executions are coordinated correctly. Data transfers between the host and the device should be synchronized to avoid accessing data that has not yet arrived or has not yet been transferred. Additionally, synchronization between kernels is crucial to guarantee that one kernel does not start executing before another has completed.
You can use CUDA events and synchronization primitives to coordinate data transfers and kernel execution. CUDA events, such as cudaEvent_t, allow you to record points in time during the execution of your CUDA code. You can use these events to measure time or to synchronize actions. Here’s an example of how to use events for synchronization:
cudaEvent_t start, stop;float elapsedTime;// Create eventscudaEventCreate(&start);cudaEventCreate(&stop);// Record the start eventcudaEventRecord(start);// Launch a kernelmyKernel<<<blocksPerGrid, threadsPerBlock>>>(deviceData);// Record the stop eventcudaEventRecord(stop);// Synchronize and calculate the elapsed timecudaEventSynchronize(stop);cudaEventElapsedTime(&elapsedTime, start, stop);// Cleanup eventscudaEventDestroy(start);cudaEventDestroy(stop);
In this example, two events (start and stop) are created and used to measure the elapsed time between recording the start and stop events. Synchronization is achieved using cudaEventSynchronize(). This ensures that the time measurement is accurate and that the kernel executes correctly in relation to other events.
Proper synchronization is particularly important when launching multiple kernels in sequence, as it helps maintain the correct order of execution and data availability.
Coalesced Memory Access
Efficient memory access patterns are crucial for optimizing GPU performance. Coalesced memory access is a memory access pattern that minimizes memory access conflicts and maximizes memory throughput. It is achieved by ensuring that threads in a warp (a group of threads executed together) access contiguous memory locations in global memory.
Coalesced memory access provides efficient data retrieval and reduces memory access overhead. When memory accesses are coalesced, threads in a warp can access a larger chunk of data in a single transaction, reducing the number of transactions required to retrieve data. This leads to improved memory bandwidth and overall performance.
__global__ void coalescedAccess(int* data) { int tid = threadIdx.x + blockIdx.x * blockDim.x; // Ensure coalesced memory access by accessing consecutive elements int value = data[tid];}
In this code, each thread in the kernel accesses consecutive elements in the global memory array, leading to coalesced memory access and improved memory throughput.
Summary
In this CUDA C++ tutorial chapter, the CUDA memory model was introduced with a practical focus on how memory choices affect performance.
The memory hierarchy exists to balance latency and bandwidth, and the principle of locality explains why caches/shared memory help.
Registers and shared memory are fast but limited; local and global memory are larger but slower.
Global memory is the most common storage for large GPU datasets, so allocation (cudaMalloc), copies (cudaMemcpy), and access patterns matter.
Coalesced global memory access is one of the highest-impact optimizations because it improves effective memory bandwidth.
Next, the natural continuation is to look at how these memory spaces interact with kernels in real workloads and how to reason about memory bottlenecks.