Overview
Digging through long research papers or other documents to identify relevant information takes a lot of time and becomes overwhelming. Now, imagine finding the most essential insights based on your questions within a matter of seconds. Well, that’s exactly what Retrieval Augmented Generation (RAG) has to offer.
In this post, we will follow a straightforward process of building an application of Retrieval Augmented Generation using LangChain, Streamlit, and the DeepSeek LLM model. We will learn how to transform documents into a searchable knowledge base and create an interactive system where users can ask questions to get the most accurate context-driven answers.
We will be developing a Retrieval Augmented Generation based research assistant in no time, with tools such as FAISS for fast document retrieval and HuggingFace embeddings to understand the meaning behind the text.
Let’s start the exciting journey.
Introduction
In this section, we shall briefly discuss Retrieval Augmented Generation (RAG), LangChain, and DeepSeek. This forms the basis upon which to build the model and understand how it operates.
Retrieval Augmented Generation (RAG):
The Retrieval-Augmented Generation (RAG), is a game-changing approach that supercharges large language models by providing them with access to external knowledge right when needed. It does not rely solely on what the model has learned, but it instead allows the model to pull in relevant information from documents, databases, or the web before crafting the response.
By using Retrieval Augmented Generation, the answers are much more accurate and trustworthy. This eliminates the frustrating moments when the model “hallucinates” or makes things up. RAG taps into recent information without the need of constant retraining to stay up to date with recent content.
In short, Retrieval Augmented Generation enables AI to handle complex questions in a smarter and more dynamic way, helping to generate more trustworthy and accurate results.
How RAG Works?
📌 Step 1: Data Preparation & Storage 📂
📥 Collect Data → Gather research papers, books, or documents. ✂️ Chunking → Split the data into smaller, meaningful pieces. 🔢 Vectorization → Convert text chunks into numerical vectors (embeddings). 📦 Store Data in Vector Database → Save embeddings in FAISS, Pinecone, or Chroma for fast retrieval.
📌 Step 2: Query Processing 🤔
❓ User Question → The user asks a question (e.g., “What is quantum entanglement?”). 🔢 Convert to Vector → The question is transformed into an embedding. 🔍 Similarity Search → The system finds the top relevant text chunks from the database.
📌 Step 3: Generate Response 📝
➕ Combine Question + Retrieved Context → The AI now has real information to work with. 🧠 Feed into LLM (DeepSeek, GPT, Llama, etc.) → The model generates an answer based on both its knowledge and the retrieved documents. ✅ Deliver an Accurate, Context-Aware Answer 🎯
We can further visualize the Retrieval Augmented Generation workflow using the following image (Figure 1).

Figure 1: Retrieval Augmented Generation (RAG) workflow
Langchain:
LangChain is a framework for building applications powered by large language models (LLMs), such as ChatGPT. It simplifies connecting LLMs to external data, remembers user-AI conversations, and enables the creation of action chains for complex workflows.
These features of Langchain help developers build powerful and interactive AI applications. By using Langchain, it is easier to integrate AI into your apps, be it chatbots, summarization tools, or something else that uses large language models.
DeepSeek:
DeepSeek is quite fast in the AI world in making a name, thanks to its powerful LLMs and practical AI tools. They focus on making AI accessible and affordable for businesses and developers, thereby enabling industries such as healthcare, finance, and tech to work smarter and faster. What’s interesting is that they are now running OpenAI close.
DeepSeek provides competitive performance at a more affordable price, and the integration tools are much easier to work into an existing system. And they’re huge on ethical AI, so that’s a win all around. So, DeepSeek is focused on scalability and user-friendliness, which makes it number one for companies looking to innovate without going over the budget.
Step By Step Guide To build a RAG-Based Research Assistant with LangChain, DeepSeek and Streamlit
In this section, we will build a Retrieval Augmented Generation based research assistant by using Langchain and Streamlit. We will be using the DeepSeek AI model to process the user query.
Import Required Libraries
The first step is to import the required libraries.
import streamlit as st
import os
from langchain_groq import ChatGroq
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains import create_retrieval_chain
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_huggingface import HuggingFaceEmbeddingsExplanation
-
Streamlit (st) → Used to create the user interface.
-
os → Helps in setting environment variables.
-
LangChain Modules → Used for text processing, retrieval, and document chains.
-
FAISS → A vector database for storing and searching embeddings.
-
PyPDFDirectoryLoader → Loads PDF documents from a directory.
-
HuggingFaceEmbeddings → Generates embeddings for text, helping with similarity searches.
Load Environment Variables
We here use the dotenv library to load API keys from a .env file.
from dotenv import load_dotenv
load_dotenv()Explanation
-
load_dotenv()→ Reads the.envfile and loads environment variables into the system. -
This ensures that API keys and tokens remain private and are not hardcoded in the script.
Load API Keys
Here we set up the API keys for Groq LLM and Hugging Face.
# Load Groq APi Key
os.environ['GROQ_API_KEY']=os.getenv("GROQ_API_KEY")
groq_api_key=os.getenv("GROQ_API_KEY")
# Load Huggingface Token
os.environ['HF_TOKEN']=os.getenv("HF_TOKEN")Explanation
-
Groq API Key → Required for using Groq’s language model.
-
Hugging Face Token → Required for accessing Hugging Face embeddings.
-
We retrieve these keys from environment variables instead of hardcoding them.
Define the Language Model (LLM)
Here, we initialize the ChatGroq LLM.
llm=ChatGroq(groq_api_key=groq_api_key,model_name="deepseek-r1-distill-llama-70b")Explanation
-
ChatGroq→ Uses the Groq API to access a language model. -
Model Name →
"deepseek-r1-distill-llama-70b"is chosen for processing responses.
Define the Prompt Template
prompt=ChatPromptTemplate.from_template(
"""
Answer the questions based on the provided context only.
Please provide the most accurate response based on the question
<context>
{context}
<context>
question:{input}
"""
)Explanation
-
The LLM is restricted to answering questions based on the provided context (retrieved from documents).
-
{context}→ Will be replaced by relevant document excerpts. -
{input}→ Represents the user’s query.
Create Vector Embeddings
This function processes PDF documents and converts them into searchable vector embeddings.
def create_vector_embedding():
if "vectors" not in st.session_state:
st.session_state.embeddings=HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
st.session_state.loader=PyPDFDirectoryLoader("data")
st.session_state.docs=st.session_state.loader.load()
st.session_state.text_splitter=RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200)
st.session_state.final_documents=st.session_state.text_splitter.split_documents(st.session_state.docs)
st.session_state.vectors=FAISS.from_documents(st.session_state.final_documents,st.session_state.embeddings)
st.session_state.embedding_ready = TrueExplanation
-
Check if embeddings exist → Avoids reprocessing if vectors are already created.
-
Load PDFs → Extracts text from all PDFs in the
"data"folder. -
Text Splitting → Breaks text into smaller chunks for better embedding and retrieval.
-
Generate Embeddings → Converts document text into vector representations.
-
Store in FAISS → Saves embeddings in a searchable database.
Configure the Streamlit App
This part helps to define the UI elements and handles user interactions.
st.title("RAG Application Using Langchain And Streamlit")
if st.button("Embed The Documents In Vector Database"):
create_vector_embedding()
st.write("Vector Database is ready")Explanation
-
App Title → Displays the app name at the top.
-
Button for embedding documents → When clicked, the PDFs are processed and embedded into FAISS.
Handle User Queries
If embeddings are ready, allow users to query the documents.
if 'embedding_ready' in st.session_state and st.session_state.embedding_ready:
user_prompt = st.text_input("Enter your query from the research paper")
if user_prompt:
retriever = st.session_state.vectors.as_retriever(search_type="similarity", k=5)
document_chain = create_stuff_documents_chain(llm, prompt)
retrieval_chain = create_retrieval_chain(retriever, document_chain)
response = retrieval_chain.invoke({'input': user_prompt})Explanation
-
Check if vector database is ready → Ensures document embeddings are created before accepting queries.
-
User Input (
text_input) → Allows the user to enter a query. -
Retrieve Similar Documents → Searches for the top 5 most relevant document chunks.
-
Create Processing Chains →
document_chain→ LLM generates a response based on retrieved documents.retrieval_chain→ Combines the retriever and document chain to produce the final answer. -
Invoke Chain → Sends the query to the LLM and gets a response.
Display Results & Document Similarity
The AI-generated answer is displayed, along with retrieved documents for transparency.
st.write(response['answer'])
with st.expander("Document similarity Search"):
if 'context' in response:
context_docs = response['context']
similarity_scores = response.get('similarity_scores', [None] * len(context_docs))
for i, (doc, score) in enumerate(zip(context_docs, similarity_scores)):
st.write(f"Document {i+1}:")
st.write(doc.page_content)
if score is not None:
st.write(f"Similarity Score: {score}")
st.write('------------------------')
else:
st.write("No context found in the response.")Explanation
-
Display AI Response → Shows the generated answer.
-
Expandable Section for Similarity Search → Shows retrieved documents along with similarity scores. Helps the user verify the AI’s response by checking which document parts contributed to the answer.
You can also check the flowchart below (Figure 2) to better understand how the above code of the Retrieval Augmented Generation application works.
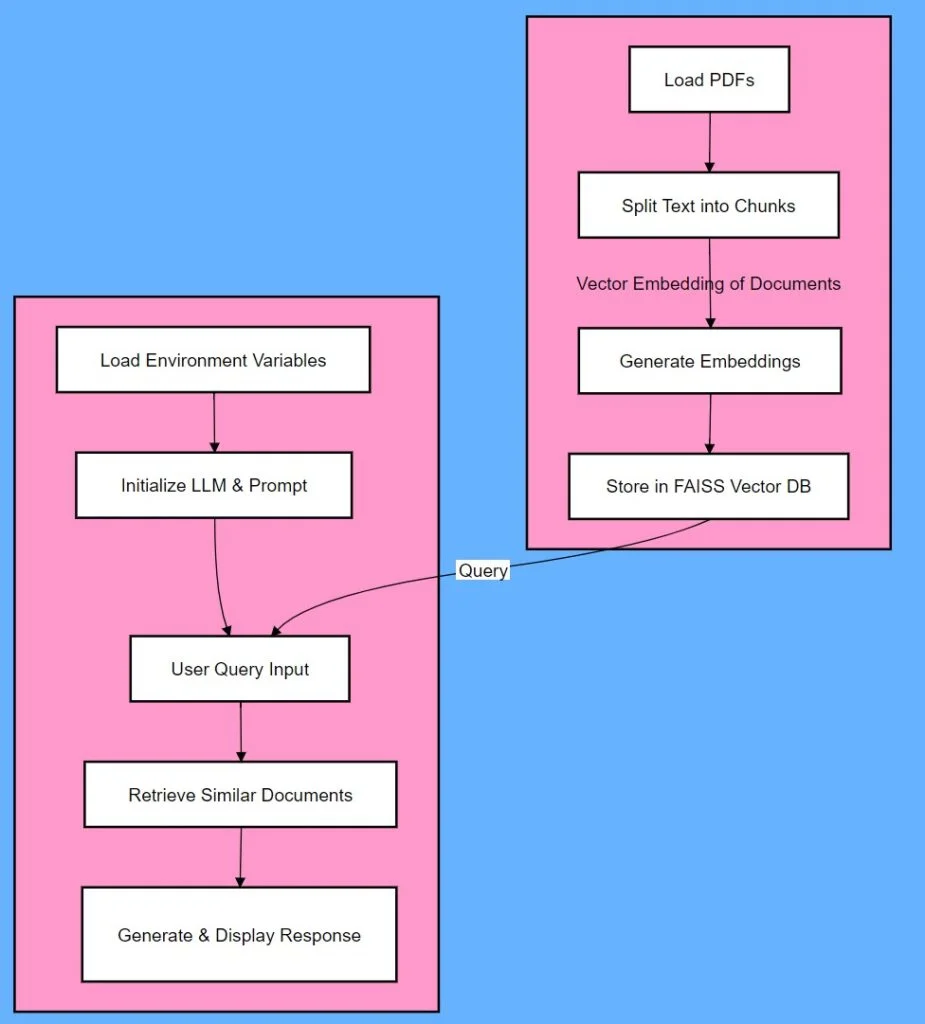
Figure 2: Flowchart depicting document processing and query retrieval in a Retrieval Augmented Generation application
Visualize The Results
The figures below (Figure 3 and Figure 4) show the answer to the question along with sections in the document with a similarity score; therefore, you can understand how the information was retrieved and generated.
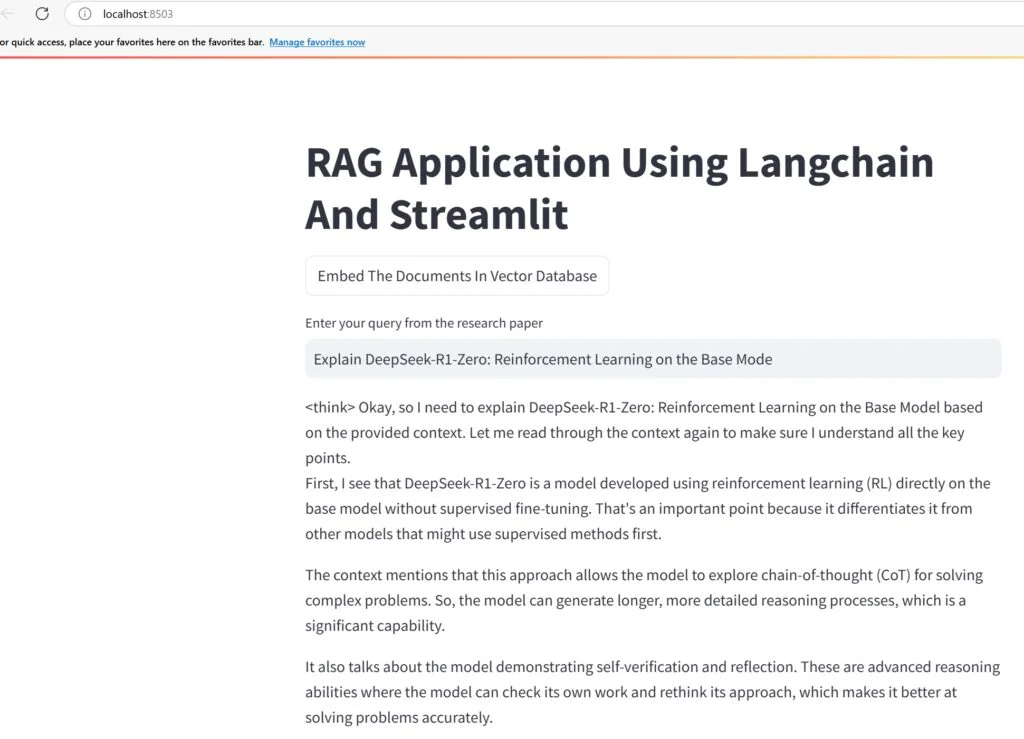 Figure 3: Output generated by the Retrieval Augmented Generation based research assistant
Figure 3: Output generated by the Retrieval Augmented Generation based research assistant
 Figure 4: Document similarity search view showing retrieved context and similarity score
Figure 4: Document similarity search view showing retrieved context and similarity score
Conclusions
In this article, we successfully developed a Retrieval Augmented Generation (RAG) application using LangChain, DeepSeek, and Streamlit.
We started by breaking PDFs into smaller chunks and converting them into vector embeddings, which were then loaded into a FAISS database for efficient retrieval.
By integrating LangChain, Hugging Face, and Streamlit, we built a seamless system for document processing, embedding generation, and interaction with a language model.
This system delivers intelligent and contextually relevant responses, showcasing how Retrieval Augmented Generation bridges the gap between static knowledge and dynamic queries, making AI interactions more accurate and insightful.
References And Related Articles
What is retrieval augmented generation?
Ollama: Supercharge Your Chatbots with LangChain IntegrationOllama
What is LangChain and how to use it: A guide
Find the source code here: Retrieval Augmented Generation
What is Retrieval Augmented Generation (RAG) and why is it useful?
The retrieval augmented generation is like giving superpowers to any AI; it does not simply rely on whatever it has memorized but actively searches for relevant information before answering questions. This makes responses accurate and grounded in actual data. It will help in limiting the chances of the AI making things up. Plus, they are always up to date, without the need for retraining!
How does LangChain help in building AI applications?
LangChain makes working with AI models extremely easy. It helps developers connect large language models with information from the outside world, retain memory of conversations in progress, build more interactive and intelligent applications, and so on. Whether you're building a chatbot, a virtual research assistant, or a summarization tool, just think LangChain.
Why choose DeepSeek LLM for this RAG application?
DeepSeek is the fastest, cheapest, and easy to integrate. Low-cost yet quality responses using AI to feed into businesses and developers wanting great AI features on a budget. It is ethically designed regarding AI principles, making it a great competition to other big-name models.
