Overview
Imagine you are tasked to train a deep-learning model with limited data samples. Can you train a deep-learning model that performs satisfactorily with such a small dataset? Most likely, you will doubt getting good results with the deep learning model with limited data. Is there a solution? Fortunately, yes, and the answer is transfer learning.
Transfer learning is a machine learning technique in which the knowledge gained from solving one problem is used to solve another different but related problem. For example, if you’re training a classifier to recognize whether an image contains food, you could also use the information it learned from the training to identify beverages. Here is the exciting part: Using transfer learning, you can develop a new model specific to your needs with limited data and limited computational power.
In this article, you will learn the benefits of transfer learning, how to select pre-trained models, deep dive into how transfer learning works, and how to implement transfer learning. We hope you will enjoy the article.
What Is Transfer Learning?
Here, we will try to understand transfer learning with the help of an analogy.
From our real-world experience, we know that the knowledge and skills we gain by accomplishing a task can be beneficial when approaching another similar task. Imagine that you are a carpenter trying to learn how to make a chair.
From practical experience making a chair, you will better understand various carpenter tools such as saws, chisels, and drills. You will also learn about different wood types and how they affect the quality of the chair. As you keep learning, you may try a more complex project, such as making a table. Although you will encounter new obstacles, you quickly realize that many of the skills and principles you learned in making the chair are also relevant to making a table.
A similar concept applies to transfer learning, where the knowledge gained by a machine learning model for one task can be used for another task. For example, you have trained a neural network on various features of vehicles, such as wheels, windows, and shapes from photographs.
Now, if you want to train a different model to recognize particular types of cars, you don’t need to start from zero. You can take the vehicle recognition model and fine-tune it to your specific needs, such as car identification.
Just as a carpenter applies the skills, transfer learning allows us to apply the knowledge a machine learning model gained from one task to another related and often more complicated task.
What are The Benefits Of Transfer Learning?
There are several benefits of using transfer learning, such as saving training time, superior performance of neural networks (in most cases), and requiring less data. Here, we will explain the benefits of transfer learning in more detail.
Save Training Time
Using transfer learning, you can save a lot of time in training a model. You don’t have to start from scratch. Instead, you transfer the patterns and knowledge learned by a pre-trained model to build a new model.
Require Less Data
Large amounts of input data are often required to build a new model from scratch. Instead, you use transfer learning to develop a model with a smaller dataset and achieve high performance. In transfer learning, you use a pre-trained model, which has already learned many valuable features during the pre-training task, leading to superior performance.
Enhanced Performance
Transfer learning will improve model performance when the pre-trained model is developed on a large and diverse dataset. You can further improve the accuracy of the model by fine-tuning.
Adaptability
Transfer learning is highly adaptable and can be used successfully for various tasks, such as computer vision and natural language processing. This makes transfer learning a valuable tool across various domains.
Generalization
By transferring knowledge from a related task, the model can generalize better to new tasks. This is because it can utilize the abstract representations learned previously.
How To Select A Pre-trained Model?
Task Compatibility
What task do you want to achieve with your model: image classification, object detection, natural language processing, or something else? You can explore various pre-trained models in popular frameworks like TensorFlow Hub, Hugging Face’s Transformers, or PyTorch Hub based on your task.
To develop a model for computer vision tasks, you may choose pre-trained models like VGG, ResNet, Inception, and EfficientNet. Popular pre-trained models for NLP tasks are BERT, GPT, RoBERTa, and T5. Table 1 lists popular pre-trained models in various domains.
| Domain | Model Name | Description | Developer |
|---|---|---|---|
| NLP | BERT | Contextual word understanding. | |
| GPT-3 | Text generation and understanding. | OpenAI | |
| RoBERTa | Optimized BERT. | Facebook AI | |
| T5 | Text-to-text tasks. | ||
| XLNet | Autoregressive model. | Google/CMU | |
| Computer Vision | ResNet | Image recognition. | Microsoft Research |
| VGGNet | Deep convolutional network. | University of Oxford | |
| EfficientNet | Scalable image classification. | ||
| YOLOv4 | Real-time object detection. | Alexey Bochkovskiy | |
| Faster R-CNN | Object detection with region proposals. | Microsoft Research Asia | |
| Speech Recognition | DeepSpeech | End-to-end speech recognition. | Mozilla |
| Wav2Vec | Raw audio representations. | Facebook AI | |
| Jasper | End-to-end speech recognition. | NVIDIA | |
| Reinforcement Learning | DQN | Deep Q-learning. | DeepMind |
| AlphaGo | Go-playing AI. | DeepMind | |
| PPO | Policy optimization algorithm. | OpenAI | |
| Generative Models | StyleGAN | High-quality image synthesis. | NVIDIA |
| BigGAN | Large-scale image generation. | DeepMind | |
| VQ-VAE | High-quality image generation. | DeepMind | |
| Biomedical | BioBERT | Biomedical text mining. | Korea University |
| CheXNet | Pneumonia detection from X-rays. | Stanford ML Group | |
| DeepVariant | Genetic variant caller. |
Table 1: Popular pre-trained models across domains
Performance
Look for the pre-trained models that have shown excellent performance on tasks similar to yours. You can select the model that best balances accuracy and computational efficiency based on your requirements.
Model Size And Complexity
Model size refers to the number of parameters in a neural network. A large pre-trained model will have more parameters, and hence, it will require more computational resources for training and inference.
To select a pre-trained model, consider the trade-off between the model size and performance. Finally, you can choose the model that fits your computational resources and achieves the desired results.
Fine-Tuning Ability
Select a pre-trained model with a modular architecture and available resources that allow you to modify or fine-tune its parameters without losing its learned representations. A model with modular architectures or layers can be added, removed, or altered easily, thus providing greater flexibility for fine-tuning.
Domain Specialty
If you’re working on a task within a specific domain, such as medical imaging or legal documents, consider using pre-trained models that have been fine-tuned or designed specifically for that domain. These domain-specific models can provide better out-of-the-box performance compared to general-purpose models.
Decoding Transfer Learning: A Visual Guide to Model Adaptation
The figure below (Figure 1) gives a high-level overview of how transfer learning works. The figure has a source model (pre-trained network) and a target model. As shown in the figure, there is also the transfer of knowledge from the source model to the target model, which illustrates how transfer learning works.
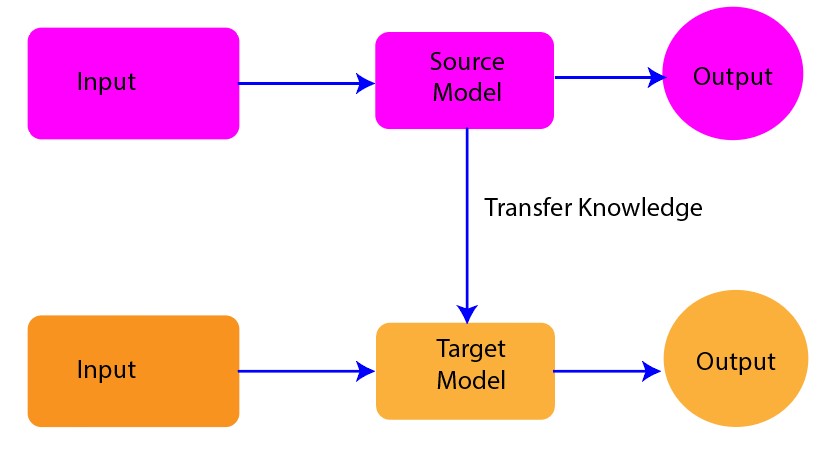
Figure 1: High-level overview of transfer learning (source model to target model)
Now, see another figure (Figure 2) showing how transfer learning works in practice. Here is the explanation of the key elements depicted in the figure.
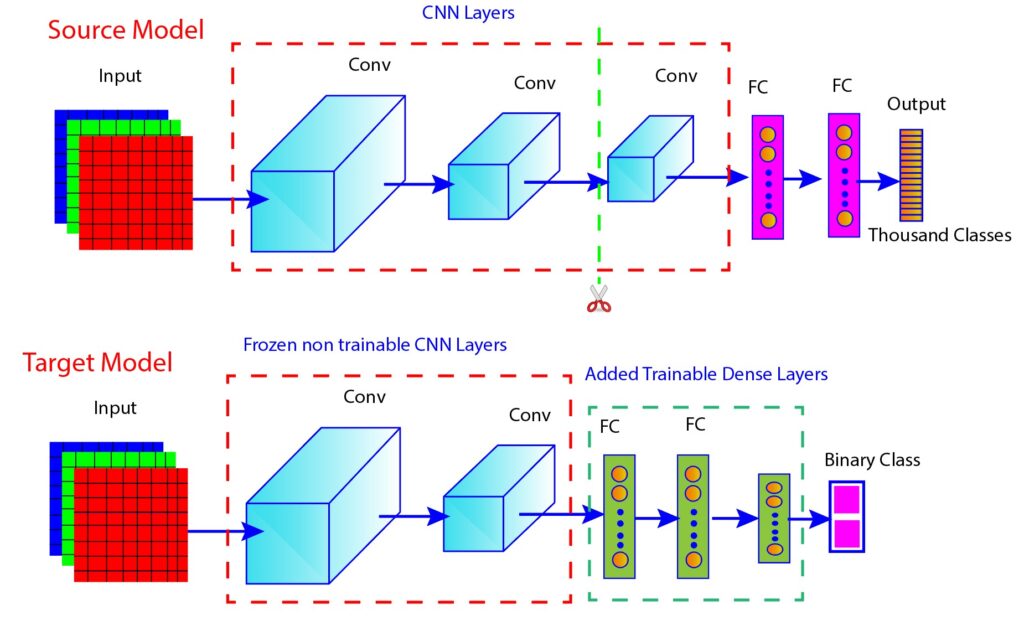
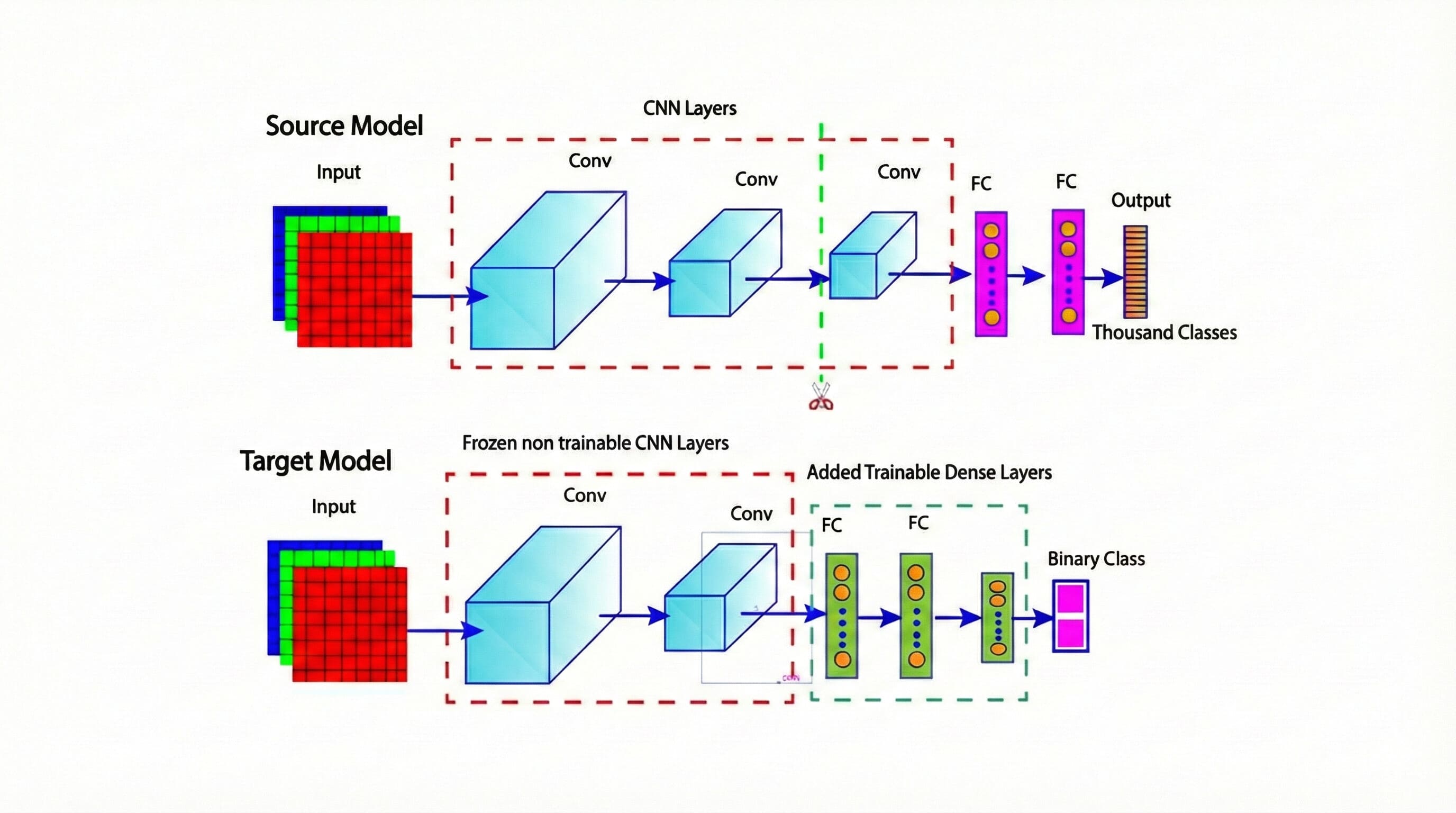
Figure 2: Transfer learning framework showing reused and trainable layers
Source Model
This is a pre-trained neural network trained on a large dataset to recognize a wide range of features. The network consists of three convolutional layers, two fully connected dense layers, and one output layer. The convolutional layers are used to identify general features from the images, while the fully connected layers are used to classify those features into a large number of classes.
Target Model
The target model reuses two convolutional layers from the source model but freezes them, meaning their weights are not updated during the training of the target model. Two new dense layers are further added to the target model. Both the dense layers are trainable, which means their weights will be updated during training to specialize the model for a new task. The output layer is designed for binary class classification, simplifying the task to a yes/no decision.
As shown in the figure above, the source model has three convolutional layers, but only two are in the target model. This design choice illustrates that all the layers of the source model are necessarily not required in the target model. The key point is that the target model can reuse some or all of the pre-trained layers from the source model and add new trainable layers to adapt to a new task.
How To Implement Transfer Learning?
Following are the steps to fine-tune a pre-trained machine learning model for a new task.
Select a Pre-trained Model
Identify a pre-trained model trained on a large dataset and perform tasks similar to the one you are interested in. If you want to develop a machine learning model for image classification, you may try pre-trained models such as VGG-16, VGG-19, ResNet-50, InceptionV3, and Xception. The popular pre-trained models for NLP tasks are Word2Vec, GloVe, and FastText.
Identify Relevant Layers
Examine the architecture of the pre-trained model and identify which layers are suitable for your specific task. The lower layers (layers close to the input) extract basic features such as edges and textures, while the higher/top layers (layers close to the output) capture more abstract concepts. You may choose to select some or all of the layers based on your task and data availability.
Remove the Output Layer
Remove the output layer of the pre-trained model and replace it with a new output layer that suits your problem. For example, you must add a softmax layer as the output layer if working on a classification task. The number of units in the softmax layer is the number of classes in your dataset. For example, for a classification task with ten classes, add a Dense layer with ten units and a softmax activation function:
model.add(Dense(10, activation='softmax'))Freeze the Layers
Once you identify the relevant layers, freeze them to prevent the weights from updating during training. It helps to preserve the features extracted by these layers throughout the fine-tuning process. In TensorFlow/Keras, this can be done by setting layer.trainable = False for each layer you want to freeze:
for layer in base_model.layers:
layer.trainable = FalseIntroduce New Layers
Add new layers to the top of the pre-trained model to adapt it to the new task. Adding new layers will allow the model to learn the task-specific features and representations that may not be captured by the pre-trained layers alone.
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))Compile the Model
Now, compile the model with an appropriate loss function, optimizer, and evaluation metrics. Set the parameters while considering the nature of the data and task (e.g., classification, regression) you are solving. For a classification task, you might use:
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])Fine-Tune the Model
Train the modified model on your dataset. You can unfreeze some of the previously frozen layers if you want to fine-tune them along with the new layers. Use a small learning rate to avoid drastic changes to the pre-trained weights. For example,
from tensorflow.keras.callbacks import ReduceLROnPlateau
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.001)
model.fit(train_data, train_labels,
epochs=10,
validation_data=(val_data, val_labels),
callbacks=[reduce_lr])Conclusions
Transfer learning is a powerful technique for developing machine learning models with limited data samples. In transfer learning, the knowledge of a pre-trained model is transferred to build a new machine-learning model, which can save time on training and achieve results even with small datasets.
This article covered fundamental transfer learning concepts, such as the benefits of transfer learning models, how transfer learning works, and the necessary steps to implement transfer learning.
Transfer learning is highly adaptable and efficient, making it an invaluable tool in modern AI and machine learning workflows. As you continue to learn more about transfer learning and apply it, you will find that the potential applications of transfer learning are vast. You can create sophisticated models tailored to your specific needs with greater ease and precision.
We hope this article is helpful to you. Stay curious, keep experimenting, and embrace the transformative capabilities of transfer learning to push the boundaries of what your models can achieve.
Frequently Asked Questions
What is transfer learning?
Transfer learning is a machine learning technique where a model trained on one task is used for a different but related task. This allows the use of pre-existing knowledge and reduces the need for large datasets.
What are the benefits of transfer learning?
Transfer learning helps reduce the training time, lower the data requirements, enhance performance using pre-learned features, and improve generalization capabilities by using the knowledge of previous tasks.
How do you implement transfer learning?
To implement transfer learning, use the following steps in order: select a suitable pre-trained model, identify and retain layers that capture essential features of the data, remove and replace the output layer to fit your new task, freeze the necessary pre-trained layers to keep their weights unaltered during training, introduce new layers as per the requirements of your specific task, compile the model with appropriate parameters, and fine-tune the model on your dataset.
