Introduction
Do you know how residual networks (ResNet) revolutionized deep learning? Understanding ResNet is like exploring a new dimension in the universe of artificial intelligence. Before the introduction of ResNet, deep learning models (having a large number of layers) often suffered from vanishing and exploding gradient problems.
In 2015, Microsoft researchers addressed these issues by introducing an innovative architecture known as ResNet. This breakthrough helped to successfully build deep neural networks with many layers ranging from 18 to 152 layers without sacrificing performance. The secret? ResNet uses skip connections that allow the flow of information across various layers seamlessly.
The impact of ResNet was quite evident when it won the ImageNet competition in 2015 by a significant margin while achieving the top-5 error rate of just 3.57%. The versatility and adaptability of ResNet made it a cornerstone in many tasks, such as image classification, object detection, segmentation, facial recognition, transfer learning, and medical imaging.
ResNet represents a paradigm shift that has inspired many other deep learning architectures and will continue to influence the future of AI. It demonstrates that progress is not only about going deeper but also about developing more intelligent pathways for learning. Continue reading this article if you want to learn more about the principles and architecture of Resnet.
Understanding The Fundamentals ResNet
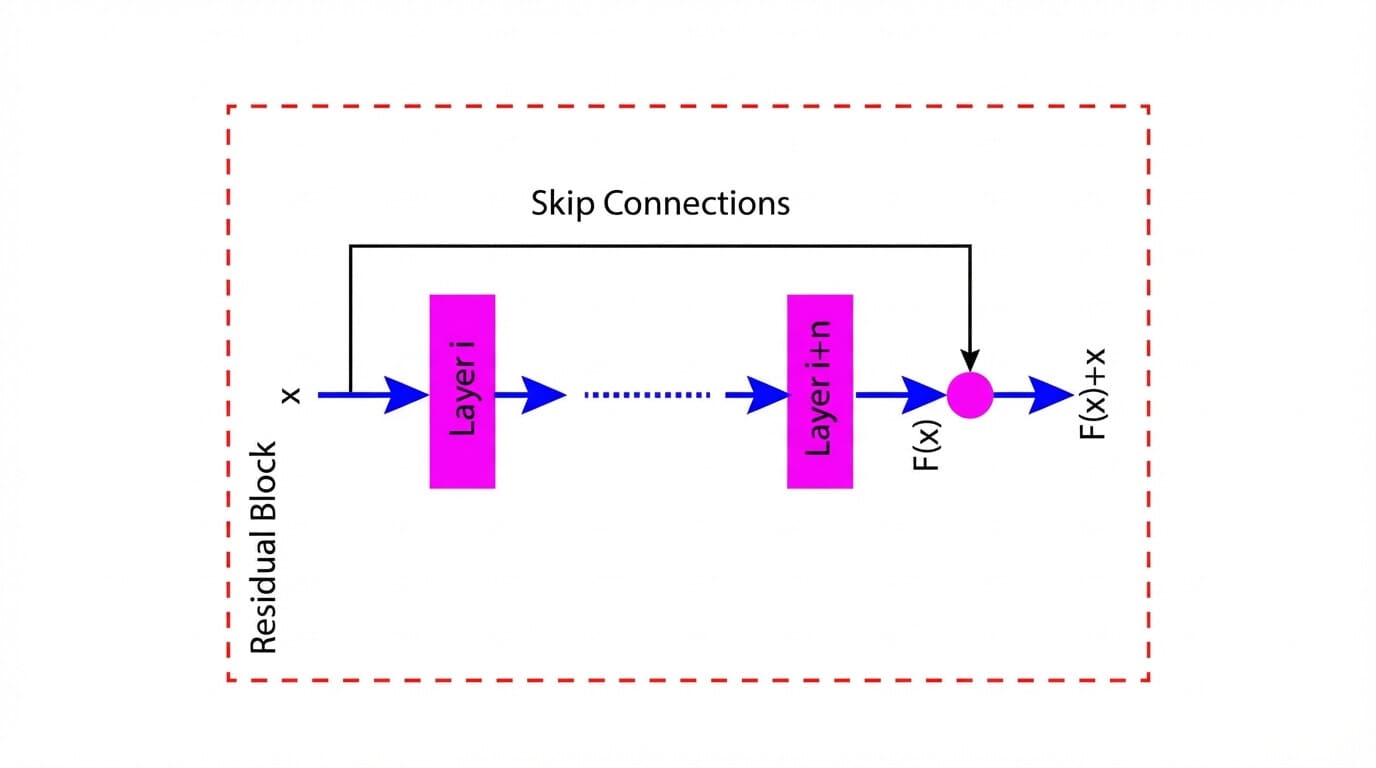
Here, we will explain ResNet with the help of an illustrative example. The figure below (Figure 1) shows a traditional feed-forward network and a resnet with a residual connection.
In the traditional feed-forward network, the output of each layer serves as an input for the next layer. Fig.(a) shows that the input (x) is processed through a series of layers, with the output of each layer becoming the input to the subsequent layer, ultimately producing a final output F(x).
Now consider the residual block, as shown in Fig.(b). Here also, the network processes the input x through a series of layers. However, the network also has a shortcut or skip connection that bypasses one or more layers by adding the input x to the output of the last layer, resulting in F(x)+x.
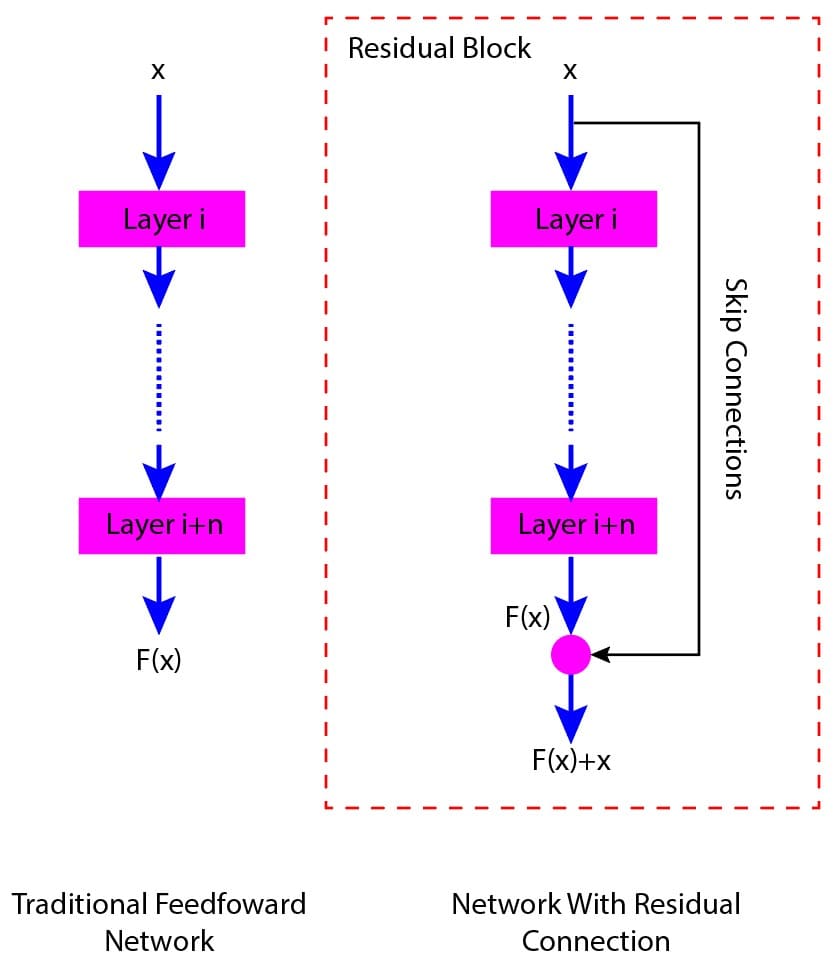 Figure 1: Traditional feed-forward network vs residual connection in ResNet
Figure 1: Traditional feed-forward network vs residual connection in ResNet
In the above example, the skip connections that take an input X and produce an output F(x) + x is a fundamental concept of ResNet. The architecture is typically implemented using a residual block or building block. Moreover, the residual block may also include an activation function, such as ReLU, that can be applied to the output F(x)+x.
Key Components Of residual networks
Convolutional Layers
Convolutional layers are one of the fundamental components of ResNet. They are responsible for extracting features from input images through convolution operations. In the convolutional operation, filters are applied to the input data to detect patterns and characteristics at different spatial hierarchies.
Residual Block
The residual block is the fundamental building block in the residual network. It helps to bypass one or more layers through a skip connection (shortcut connection).
In a traditional neural network, a layer’s output is the next layer’s input. However, in a network with a residual block, each layer within the block has an additional skip connection (shortcut connection) that bypasses one or more layers. With the help of skip connections, the original input is added directly to the output of the block. The use of the residual block helps train deeper networks by addressing the vanishing gradient problem.
There are two types of residual block in ResNet.
Identity Block
An identity block is used when the input and output dimensions are the same. In this case, we can directly add the input of the block to its output using a skip connection. The figure below (Figure 2) shows an identity block where input x is directly added to the output of the block.
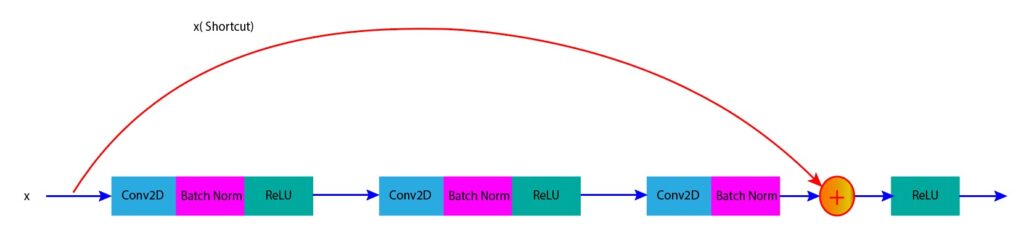
Figure 2: Identity block in ResNet (input is added directly to the block output)
Convolutional Block
A convolutional block is used when the input and output dimensions are different. This usually happens when we downsample feature maps to reduce special dimensions or the number of channels. In this case, we need to pass the input through a convolutional layer in the skip connection to match the dimension of the input with the output. The figure below (Figure 3) shows a convolutional block where the input x is passed through a convolutional layer before it is added to the output of the block.
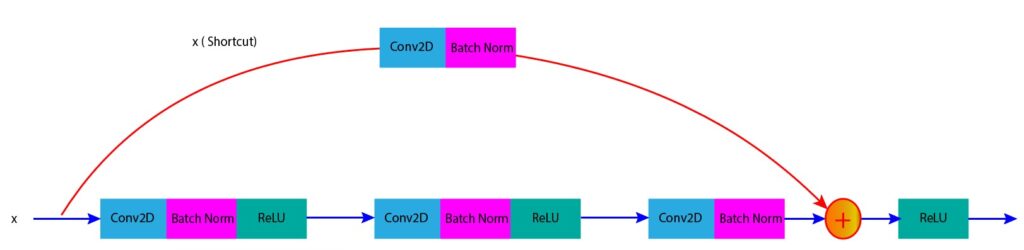
Figure 3: Convolutional block in ResNet (projection shortcut to match dimensions)
Skip Connections
Skip connections offer an alternative path for gradient flow during backpropagation in the network. Using skip connections, gradients can directly propagate to the earlier layers instead of passing through multiple layers. This helps the network to mitigate the vanishing gradient problem.
Mathematically, we can represent the skip connection by adding the input of a layer to the output of one or more layers ahead.
Where X is the input of the block, F(X) is the residual mapping to be learned by the layers within the block, and H(X) is the final output of the residual block.
The above equation involves the element-wise addition of x and F(x), assuming their dimensions are the same.
If the dimensions differ, we need to add a linear projection Ws to match the dimensions of x and F(x).
Batch Normalization
Batch normalization is used after each convolution operation. This helps to normalize the output and improve the training process.
Activation Functions
The Rectified Linear Unit (RELU) is the activation function in ResNet architectures.
Pooling Layers
Pooling layers are used to reduce the spatial dimensions of the data as it passes through the network.
Fully Connected Layers
Fully connected dense layers are used to perform classification based on the features extracted by the convolutional layers.
SoftMax Output Layer
The ResNet model used a SoftMax output layer that outputs the probabilities for the classification task.
Why Skip Connections Matter?
Traditional deep learning models with a large number of layers are prone to the vanishing gradient problem. During the backpropagation, the gradients can become extremely small (and nearly vanish) as they propagate backward through many layers of a deep neural network. Due to this, the earlier layers may find it difficult to learn meaningful features, which may significantly impact the convergence and performance of deep neural networks.
In ResNet, skip connections are used to create shortcuts for gradients to bypass certain layers. Using these skip connections, the gradients can jump directly from one layer to another instead of traveling through all the layers sequentially. This helps the gradients to reach earlier layers directly and makes them less prone to becoming excessively small, thus mitigating the vanishing gradient problem.
Another significant issue of the deep neural network is the exploding gradient problem. This problem happens when gradients become excessively large during backpropagation, leading to unstable training due to large updates to the network weights. The use of skip connections helps to mitigate the exploding gradient problem by stabilizing the gradient flow. Skip connections prevent the weights from growing exponentially by providing a direct path for them, thus maintaining the stability of weight updates.
Before the advent of residual networks, developing a deep neural network with hundreds of layers was impractical due to the vanishing gradient problem. Now, one can easily develop a deep neural network with hundreds of layers using skip connections of residual networks. This type of very deep neural network can learn more complex features and achieve better accuracy without encountering the vanishing gradient problem.
Popular ResNet Variants
Some of the popular variants of residual networks are:
ResNet-34
The architecture consists of 34 layers. It uses simple residual blocks involving two 3×3 convolutional layers with batch normalization and ReLU activation. The input to each block is added to the output of the block, forming a residual connection. This architecture is popular as a benchmark in research due to its simplicity and lower computational requirements.
ResNet-50
The architecture consists of 50 layers involving convolutional layers, pooling layers, and fully connected layers. It uses bottleneck layers to reduce the number of parameters while maintaining depth. A bottleneck layer has three convolutional layers: a 1×1 layer that reduces the dimensions, a 3×3 layer that processes the data, and another 1×1 layer that restores the dimensions. This network is popular for object detection and segmentation tasks.
ResNet-101 and ResNet-152
The ResNet-101 consists of 101 layers, and the ResNet-152 consists of 152 layers. Both architectures use more bottleneck layers to manage the increased depth. This helps to keep the number of parameters and computational requirements manageable while benefiting from deeper network structures.
Visualize ResNet-34
The figure below (Figure 4) shows the architectural details of ResNet-34 VGG-19 and a 34 layer plain network.
-
The residual network starts with an initial convolutional layer with a 7×7 kernel size, 64 filters, and stride 2.
-
After the initial convolutional layer, there are 34 residual blocks.
-
Each block consists of two convolutional layers.
-
The figure also shows the number of filters and kernel size for each convolutional layer.
-
The figure also shows skip connections that will prevent the gradients from vanishing or exploding during training.
-
Some of them are dotted skip connections representing the dimension of input required to be increased to match the dimension of the block output.
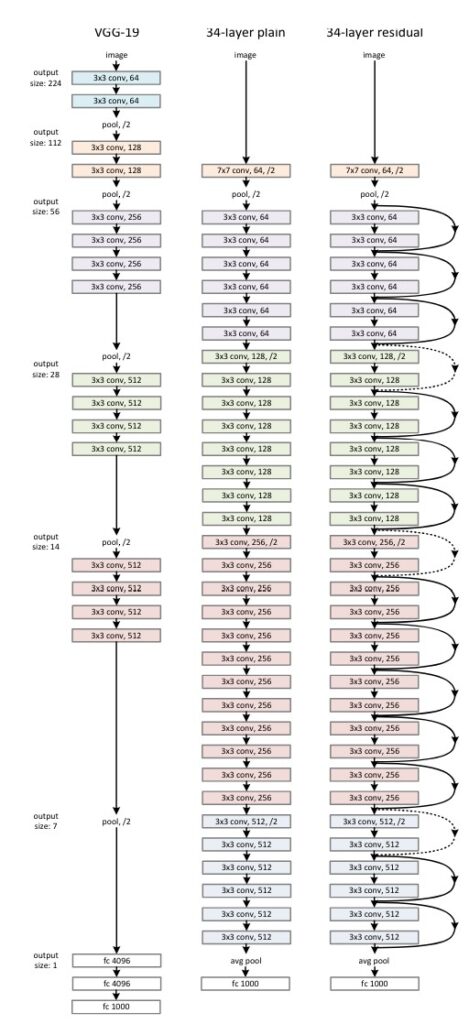
Figure 4: Architectural details of ResNet-34 compared with plain networks
Performance Analysis
Here, we will analyze the performance of two plain neural network models with 20 and 56 layers, respectively. Figure 5 shows the training and test errors of both neural networks for the CIFAR-10 dataset.
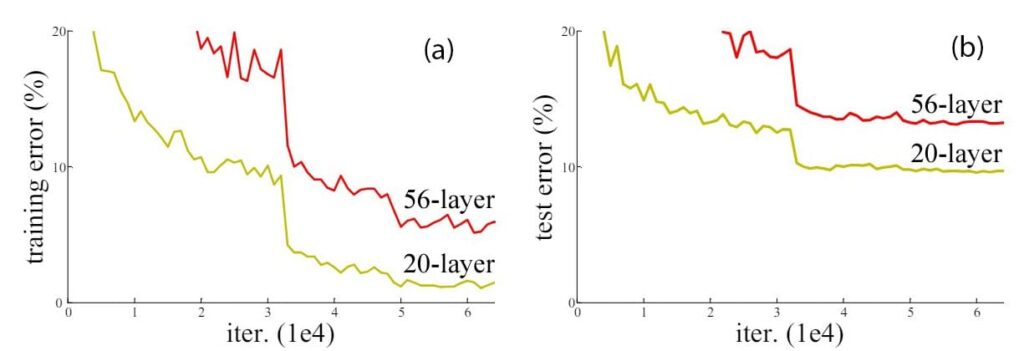
Figure 5: Training and test error of two plain neural network models having 20 and 56 layers
We observe that the training and test errors of the 56-layered neural network are higher than the 20-layered neural network. This shows that the performance of the 56-layered neural network is worse than that of the 20-layered neural network.
The degradation of the performance of the 56-layered neural network can be attributed to challenges such as vanishing gradient problems, overfitting, and optimization difficulties associated with deeper networks.
Let us analyze the performance of another set of plain neural networks having 18 layers and 34 layers on the ImageNet dataset. In Figure 6, the thin curves represent training errors, and the thick curves represent validation errors.
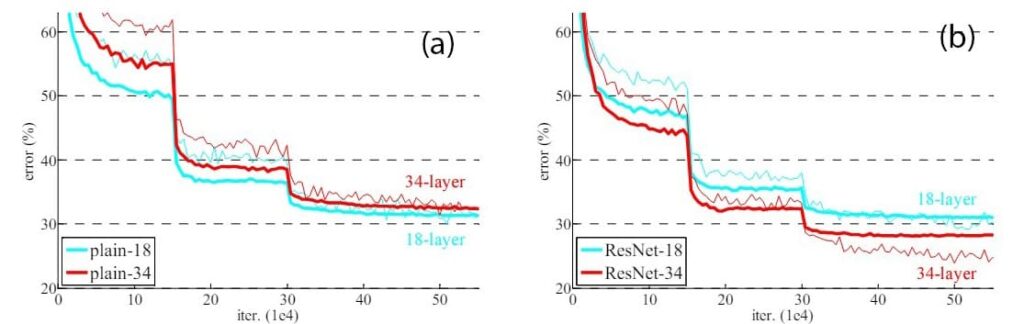
Figure 6: (a) Training and validation error of two plain neural network models having 18 and 34 layers (b) Training and validation error of two ResNet models having 18 and 34 layers
Fig(a) shows the training and the validation error with respect to iteration number for both the plain neural networks. We observe that the training and validation errors of the 34-layered neural network are higher than the 20-layered neural network. This indicates the poor performance of the 34-layered neural network over the 18-layered neural network. The poor performance of the 34-layered neural network can be attributed to challenges such as vanishing gradient problems, overfitting, and optimization difficulties associated with deeper networks.
Let us now analyze Fig.(b). Here, we replaced both the plain neural networks with ResNet models while keeping the same number of layers. The figure shows that the training and validation errors for the 34-layered ResNet model are less than the 18-layered model. Thus, we can say that the performance of the residual network keeps improving if we increase the number of layers.
In summary, the ResNet model can handle deep architecture better than plain networks. The ResNet can mitigate the vanishing gradient problem better than plain neural networks, improving performance.
Conclusions
This article provides valuable insights into the development of residual networks (ResNet). We learned many fundamental details and key components of residual networks. We also learned why skip connection matters and how it helps to mitigate the vanishing and exploding gradient problem.
This article also provided a performance analysis based on previous research. From the study, we understood that with a ResNet model, we can handle deep architecture better than plain networks. The residual network can effectively mitigate the vanishing gradient problem better than plain neural networks, resulting in better model performance.
Frequently Asked Questions
Is ResNet better than CNN?
ResNet, also known as Residual Network, is a type of convolutional neural network (CNN). The ResNet is considered better than traditional CNNs for tasks that require deeper networks such as image recognition or object detection. The ResNet has skip connections or shortcuts that help to address the vanishing gradient problem, unlike the CNN.
Is ResNet and RNN same?
They are not the same. ResNet stands for Residual Neural Network and RNN stands for Recurrent Neural Network. ResNet is mainly used for tasks like image classification, object detection, and image segmentation. While the RNNs are used for sequence data processing tasks such as language modeling, speech recognition, and time series prediction.
How many layers are in ResNet?
ResNet architectures typically come in several versions, denoted by the number of layers they have. The original ResNet, introduced by He et al. in 2015, has different variants with varying numbers of layers, such as ResNet-18, ResNet-34, ResNet-50, ResNet-101, and ResNet-152. The number in the name indicates the total number of layers in the network, including both convolutional and fully connected layers.
What is ResNet used for?
ResNet can be used for image classification, object detection, image segmentation, facial recognition, natural language processing, and speech recognition. It can train very deep neural networks effectively, making it a popular choice for tasks where accuracy and performance are critical, especially when dealing with large-scale datasets such as ImageNet. ResNet can also be used.
References
Transfer Learning: Friendly Introduction
