Overview
Are you interested in knowing how computers can recognize handwritten digits or characters? How do they acquire the ability to distinguish between shapes and patterns? The answer to this lies in a specific neural network known as the convolutional neural network (CNN), which is specifically designed for processing visual information.
Among the various CNN architectures, the LeNet-5 (LeNet) architecture is considered the classic model that laid the foundation for deep learning. The model was first introduced by Yann LeCun and his colleagues in 1998 and was mainly used to recognize machine-printed characters.
In this blog post, we will explain the various layers and important features of the LeNet-5 architecture. We hope that you will get a clear understanding of the LeNet architecture once you finish the article.
A Brief History Of Lenet-5 Architecture
LeNet-5 is a widely used convolutional neural network proposed by Yann LeCun and his team at Bell Labs in 1989. Their aim was to create a neural network that could learn independently from data and extract features without relying on manual rules or templates.
The main purpose of the LeNet model was to recognize handwritten and machine-printed characters. However, in 1989, the LeNet network did not gain enough popularity due to the limited availability of hardware resources, particularly GPUs. In those days, alternative algorithms, such as support vector machines (SVMs), were more popular due to their superior performance.
Understanding Lenet-5 Architecture
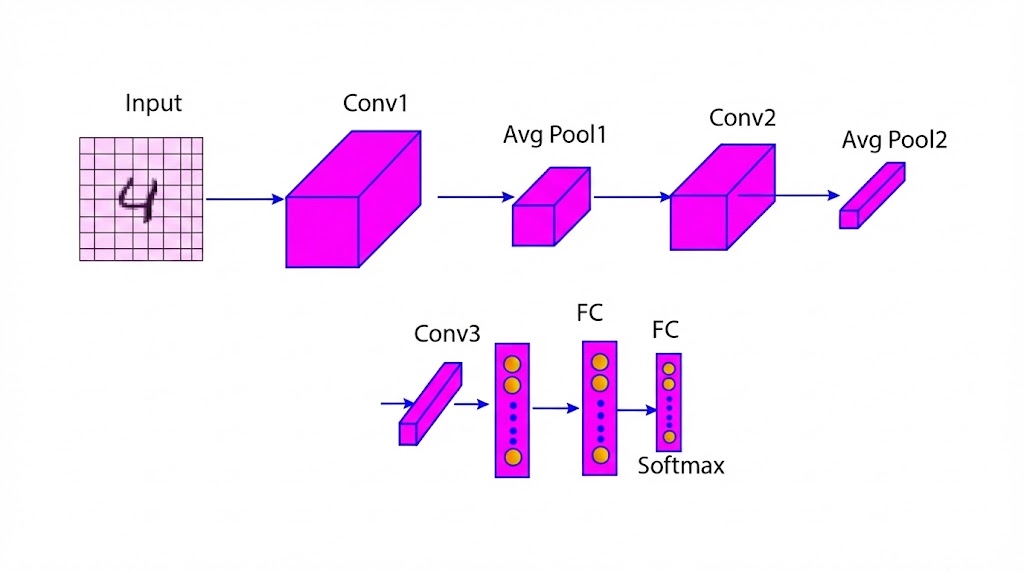
The LeNet architecture consists of seven layers: two convolutional layers, two average pooling layers, one flattening convolutional layer, and two fully-connected layers.
Here is the table summarizing the LeNet Architecture showing input size, output size, kernel size, number of filters, number of parameters, and activation function of various layers (Table 1). Let us explain each layer one by one in more detail.
| Layer | Type | Input Size | Output Size | Kernel Size | Number of Filters | Number of Parameters | Activation Function |
|---|---|---|---|---|---|---|---|
| C1 | Convolutional | 32 x 32 x 1 | 28 x 28 x 6 | 5 x 5 | 6 | 156 | tanh |
| S1 | Average Pooling | 28 x 28 x 6 | 14 x 14 x 6 | 2 x 2 | - | 12 | tanh |
| C2 | Convolutional | 14 x 14 x 6 | 10 x 10 x 16 | 5 x 5 | 16 | 2,416 | tanh |
| S2 | Average Pooling | 10 x 10 x 16 | 5 x 5 x 16 | 2 x 2 | - | 32 | tanh |
| C3 | Convolutional | 5 x 5 x 16 | 1 x 1 x 120 | 4 x 4 | 120 | 19,320 | tanh |
| FC1 | Fully Connected | 1 x 1 x 120 | 1 x 1 x 84 | - | - | 10,164 | tanh |
| Output | Softmax | 1 x 1 x 84 | 1 x 1 x 10 | - | - | 850 | softmax |
Table 1: LeNet-5 layer-wise architecture summary
Convolution Layer (C1)
This layer takes a 32×32 grayscale image as input. The images are padded with zeros to make it 32×32 if smaller.
This layer is used to capture edges, corners, and curves from the input image. In this layer, convolution operations are performed to the input image of size 32×32 with six filters of size 5×5. The output is the six feature maps of size 28×28.
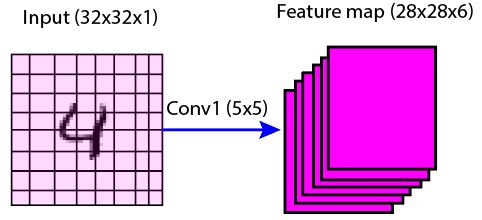
Figure 1: First convolutional layer (C1) feature map illustration
Average Pooling Layer (S1)
This layer performs average pooling with a filter size of 2×2 and a stride of two, which reduces the size of feature maps from 28×28×6 to 14×14×6 (Figure 2).
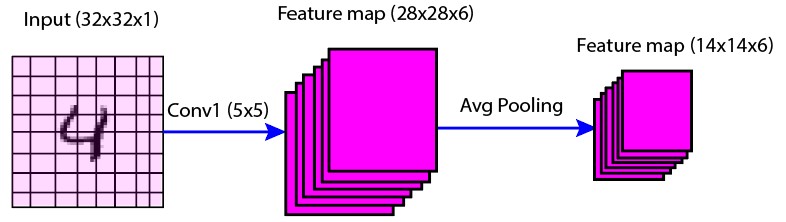
Figure 2: First average pooling layer (S1) illustration
Convolutional Layer (C2)
This layer is used to learn complex and abstract features from the images. In this layer, convolution operation is performed with 16 filters of size 5×5. The output is the 16 feature maps of size 10×10 (Figure 3).
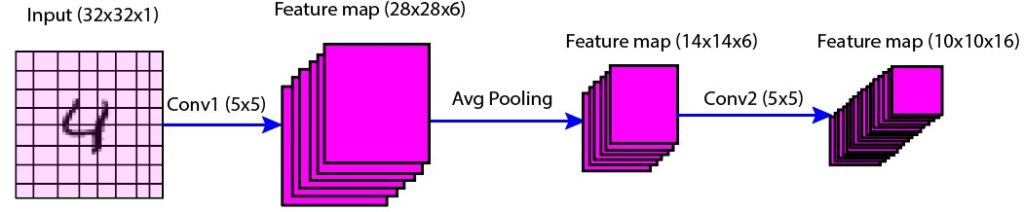
Figure 3: Second convolutional layer (C2) illustration
Average Pooling Layer (S2)
In this layer, the average pooling operation is performed again using filter size 2×2 and stride 2. The output is the 16 feature maps of size 5×5 (Figure 4).
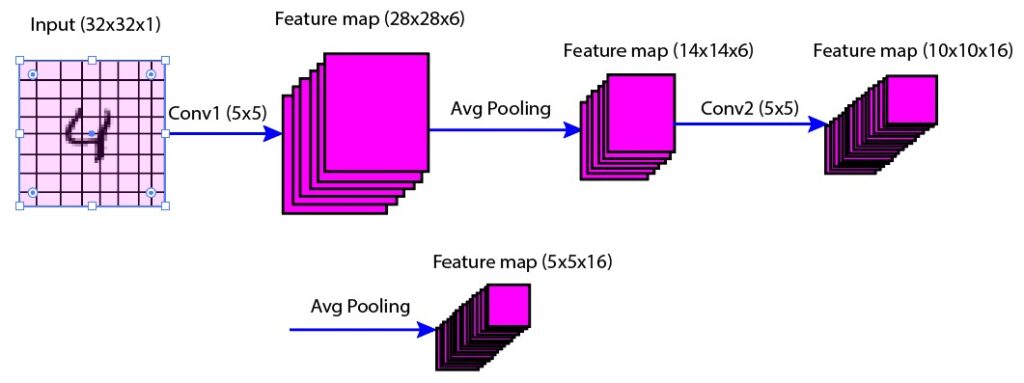
Figure 4: Second average pooling layer (S2) illustration
Convolutional Layer (C3)
This layer performs convolution operation using 120 filters of size 4×4. The output is 120 feature maps of size 1×1. This layer is similar to a fully-connected layer that converts the previous layer into a one-dimensional vector.
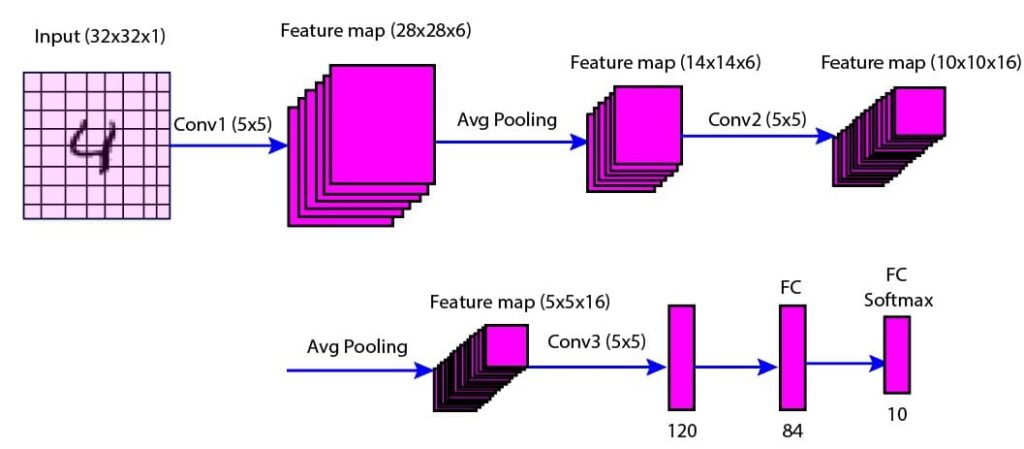
Figure 5: Pictorial representation of the LeNet-5 architecture
Fully Connected Layer (FC1)
There are 84 fully connected neurons in this layer. This layer takes the output of the convolutional layer (C3) as input and applies a linear transformation followed by a tanh activation function.
Output Layer (O1)
This is a fully connected SoftMax output layer with 10 neurons corresponding to the 10 classes of digits (0-9). This layer takes the output of the FC1 layer as input and a linear transformation followed by a SoftMax function. The output is the probability distribution over the classes.
Applications Of LeNet-5
-
Optical character recognition (OCR): Lenet-5 can be used to recognize digits and letters from scanned documents such as checks, invoices, and forms. By using Optical Character Recognition (OCR), LeNet-5 can also convert images into editable text formats.
-
Face Detection And Recognition: We can detect and recognize human faces in images or videos using LeNet-5. It can also be used for face verification, tagging, alignment, and recognition.
-
Traffic Sign Recognition: LeNet-5 can be used to recognize the shapes and symbols of traffic signs. LeNet5 can also help provide information such as speed limits, warnings, and directions to drivers or autonomous vehicles.
-
Medical Image Analysis: LeNet-5 can identify diseases, abnormalities, injuries, or tumors by analyzing medical images such as X-rays, CT scans, and MRI scans.
Conclusion
LeNet-5 is a simple yet efficient architecture that sets the foundation for convolutional neural networks (CNNs) in image recognition tasks. In this article, we discussed the various layers of the LeNet architecture and its application in various fields.
Now, we have a solid understanding of the LeNet architecture, and we can use it to develop various computer vision applications. If you want to know how to apply the LeNet to recognize the MNIST dataset, then this article is for you.
References
Lenet5:Practical Implementation
Frequently Asked Questions
What is LeNet-5 used for?
LeNet-5 is a type of convolutional neural network that can recognize handwritten digits such as zip codes provided by the U.S. Postal Service. We can use the LeNet model to recognize handwritten digits, detect objects, facial recognition, and self-driving cars.
What are the disadvantages of LeNet-5?
LeNet-5 has a shallow architecture compared to modern convolutional neural networks, which may result in slow learning rates. Moreover, the tanh activation function of the LeNet model is prone to vanishing gradient problems and not as effective as other activation functions, such as Rectified Linear Unit (ReLU) and Exponential Linear Unit (Elu). LeNet-5 is also prone to overfitting, and there is no built-in mechanism such as dropout or regularization to avoid this.
How accurate is LeNet-5?
Lenet-5 is capable of achieving 98% accuracy on the MNIST dataset, which is the standard benchmark for this type of task. However, there are some reports claiming different accuracy values for LeNet-5, such as 95.2% on a gas identification dataset or 99% on a modified version of the MNIST dataset.
