Overview
Do you know that generative adversarial networks (GANs) are one of the most promising inventions in artificial intelligence? It is an AI framework that has revolutionized how machines understand and generate new content. It was proposed by Ian Goodfellow and his research group in 2014.
Since then, it has completely transformed how we think about generative models. With the help of generative adversarial networks, we can create realistic images, enhance low-resolution photos, generate art, augment data, and even compose music.
In the generative adversarial network, two neural networks (which are known as generator and discriminator) compete against each other to generate new data from a given training dataset. For example, we can use GANs to generate new images /music from existing images/music databases. The potential applications of GANs are vast and varied across various fields, such as autonomous driving, medical imaging, art and entertainment, research and development, and beyond.
Let us go deeper into the revolutionary world of Generative Adversarial Networks (GANs).
Application Of Generative Adversarial Networks
Generative adversarial network can be used to perform a wide range of tasks across various fields.
-
Generate Examples for Image Datasets: We can use GANs to generate new images that are closely similar to images of an existing dataset. For example, we can use GAN to generate handwritten digits similar to the MNIST dataset or photographs of small objects identical to the CIFAR-10 dataset.
-
Generate Photographs Of Human Faces: GANs can be used to generate realistic human faces that look convincing and diverse. The application includes creating avatars, generating training data for face recognition models, and even generating faces like celebrities.
-
Generate Realistic Photographs: GANs can be used to generate high-quality photographs of various objects, landscapes, and scenes.
-
Generate Cartoon Characters: Another potential application of GAN is to produce cartoon-style characters, helping to bridge the gap between realism and artistic expression. These cartoon-style characters can be used in animation, gaming, and entertainment.
-
Image-to-image Translation: GANs can be used to transform images from one form to another, such as converting satellite images to maps, black-and-white photos to color photos, and day-to-night image conversion.
-
Text-to-Image Translation: GANs have the ability to create images from textual descriptions.
-
Image-To-Photo Translation: We can use GAN to enhance or modify images based on semantic information. For example, we can transform sketches into realistic photos.
-
Other Applications: GAN can be used to create new human poses, generate frontal views of images from angled faces, photo blending, photo inpainting, clothing translation, video prediction, 3D objection generation from 2D images, and many more.
Understanding Generative Adversarial Networks Through an Analogy
Generative adversarial networks involve dynamic interplay between two neural networks: the generator and the discriminator. Let us illustrate how both components work in GAN with the help of a hypothetical example.
Imagine a game between a counterfeiter (the Generator) trying to make fake currency and a cop (the discriminator). At first, the counterfeiter shows the cop some fake currency. The cop quickly identifies the money as fake and explains why he thinks the money is fake. The counterfeiter carefully listens to what the cop suggests and tries to make better-quality fake currency. However, the cop still manages to identify the money as fake and gives feedback on how to improve it further. Based on the input from the cop, the counterfeiter improves the money further.
This cycle continues until the fake currency becomes indistinguishable from the real currency, making it difficult for the cop to tell the difference. This is how GAN works in layperson’s terms.
Architecture Of GANs
The architecture of Generative Adversarial Networks consists of two main components: generator and discriminator. In the section below, we will briefly explain both the components.
The figure below shows the basic structure of a GAN (Figure 1).
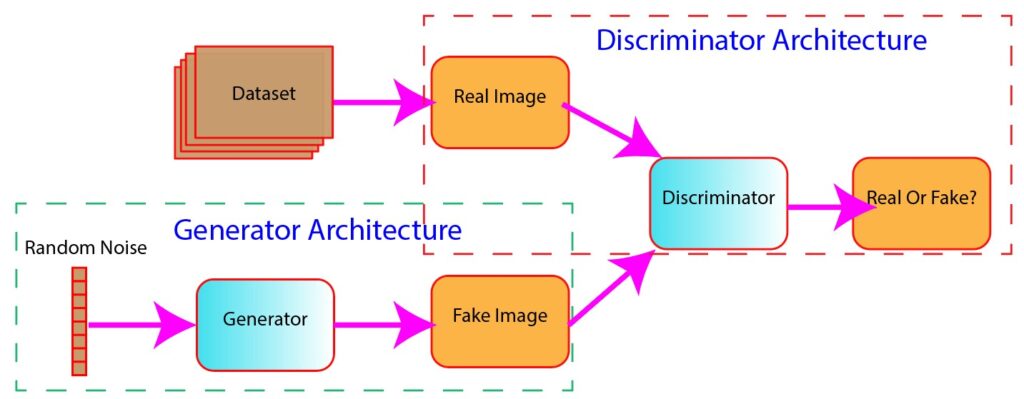
Figure 1: Basic structure of generative adversarial networks (GANs)
Generator Model
The generator is a neural network that takes random noise typically sampled from normal distribution as input and transforms it through up-sampling and convolution operations to generate realistic outputs. Essentially, the generator aims to deceive the discriminator into believing that the generated samples are real by producing synthetic data that closely resembles the training dataset.
Discriminator Model
The discriminator is a neural network used to check whether input data is real or fake. The model takes the real and synthetic data as input and outputs a probability score, indicating the likelihood that the input is real or fake.
Training Generative Adversarial Networks: A Two-Player Game
The training process of GAN can be visualized as a two-player minimax game. In this game, the generator and discriminator are trained simultaneously but with conflicting objectives.
The role of the generator is to create synthetic data from random noise and make them realistic enough to deceive the Discriminator. Essentially, the generator aims to minimize its loss in creating realistic data while simultaneously maximizing the loss of the discriminator, making it increasingly difficult for the discriminator to distinguish real and fake data.
Conversely, the objective of the discriminator is to accurately identify the real data (from the actual dataset) and fake data (generated by the generator). To achieve this, the discriminator tries to minimize its loss (so that it can correctly classify real and fake data) while simultaneously maximizing the loss of the generator in creating realistic data.
How To Train The Generator Model?
-
Generate Random Noise: The generator begins by sampling random noise (a vector of random variables) as initial input.
-
Transform The Random Noise Into Synthetic Data: The generator model then transforms this random noise into synthetic data using up-sampling and convolution operations to create data that resembles the training dataset.
-
Forward The Synthetic Data To The Discriminator: The generated synthetic data is forwarded to the discriminator, which evaluates whether it is real or fake.
-
Compute Loss: The generator incurs a penalty if the generated data is deemed fake. The loss is computed by comparing the discriminator’s evaluation of the generated output with the ground truth labels.
-
Perform Backpropagation: The backpropagation algorithm adjusts the generator weights, aiming to minimize the loss and improve the output quality. During backpropagation, the gradients flow from the discriminator to the generator, which guides the parameter updates.
How To Train The Discriminator Model?
-
Receive Real and Synthetic Data: Both the real data from the training dataset and synthetic data from the generator act as input in the discriminator model.
-
Compute Loss for Real Data: The discriminator computes a loss by comparing its evaluation to the ground truth labels (1 for real data).
-
Compute Loss for Synthetic Data: The discriminator computes a loss by comparing its evaluation to the ground truth labels (0 for fake data).
-
Total Discriminator Loss: The total discriminator loss is the summation of the losses computed for real and synthetic data.
-
Perform Backpropagation: Adjust the discriminator weights by applying the backpropagation algorithm to minimize the total loss. This will improve the ability of the discriminator to distinguish between real and fake data.
Future Directions
In the future, generative adversarial networks (GANs) are expected to evolve significantly. Some of the anticipated advancements are:
-
Improved Models: We can expect more efficient and precise generative adversarial networks in the future due to continuous advancement in computing power and algorithmic innovations.
-
Hybrid Approaches: Many novel models with powerful generative capabilities will be developed in the near future by integrating generative adversarial networks with various deep learning models such as Transformers, Physics-Informed Neural Networks (PINNs), Language Models (LLMs), and Diffusion models.
-
Ethical Considerations: As generative adversarial networks expand, many ethical issues will appear in the near future, such as issues of biases, privacy, and fairness linked with GAN-generated content.
-
Applications Beyond Images: Although generative adversarial networks have been primarily used for image generation, they are now being applied to generate text, music, and other creative content.
Conclusions
Generative adversarial networks, developed in 2014, are a major breakthrough in artificial intelligence, transforming how machines generate and comprehend content. With the help of generative adversarial networks, we can create realistic images, high-quality photographs, art, and music, with applications spanning across various fields such as autonomous driving, medical imaging, art, and entertainment.
We can visualize the GAN as a dynamic interplay between two neural networks: the Generator and the Discriminator. The generator is used to create synthetic data from random noise, with the aim of deceiving the Discriminator while the Discriminator is used to differentiate between real and fake data.
Looking forward, the future of generative adversarial networks is extremely promising. More algorithmic innovations and improved computing power will lead to more efficient and precise models in the future. For example, hybrid approaches integrating GANs with other deep learning models will unlock new capabilities and applications. However, ethical considerations regarding biases, privacy, and fairness in generated content will become increasingly important as GANs continue to evolve.
In conclusion, generative adversarial networks have transformed the way we approach generative models and have opened up a world of possibilities for creative AI applications. As researchers and practitioners continue to explore the potential of GANs, we can expect further groundbreaking developments that will continue to push the boundaries of AI-generated content.
Frequently Asked Questions
What is a generative adversarial networks?
A generative adversarial network is a machine-learning model having two neural networks: the generator and the discriminator. They compete against each other to generate new data from a given training dataset. For example, you can use GANs to create new images from existing images.
Is GAN supervised or unsupervised?
Generative adversarial networks (GANs) are unsupervised learning models. They can produce realistic data without using labeled data.
What is the difference between the generator and the discriminator in a GAN?
Generative Adversarial Networks (GANs) involve a dynamic interplay between two neural networks: the generator and the discriminator. The generator creates fake data that resembles real data, while the discriminator's task is to determine whether the data is real or fake. This adversarial process continues until the generator produces highly realistic data that the discriminator can no longer distinguish from real data.
Further Readings
Gentle Overview Of Generative Adversarial Networks
Generative Adversarial Networks: An Overview
