Overview
Do you know that AlexNet architecture is one of the most influential architectures in deep learning? It is a deep convolutional neural network (CNN) proposed by Alex Krizhevsky and his research group at the University of Toronto.
AlexNet won the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2012. It outperformed the previous state-of-the-art model by a significant margin by achieving a top-5 error rate of 15.3%, which was 10.8% lower than the error rate of the runner-up.
The invention of AlexNet is regarded as one of the breakthrough inventions in computer vision. It demonstrated great potential in deep learning by introducing many key concepts, such as using the rectified linear unit (ReLU) activation function, data augmentation, dropout, and overlapping max pooling. The success of AlexNet inspired many convolutional neural network architectures such as VGG, ResNet, and Inception.
If you want to explore more about the AlexNet architecture, you have come to the right place. In this blog post, we will explain the architecture of AlexNet and why it uses ReLU, overlapping max pooling, dropout, and data augmentation. So, let us dig deep into the article.
Understanding The AlexNet Architecture
The architecture of AlexNet comprises five convolutional layers, three fully connected layers, and one SoftMax output layer. The input is an RGB image of size 227x227x3, and the output is the probability of the image belonging to one of the 1000 object categories.
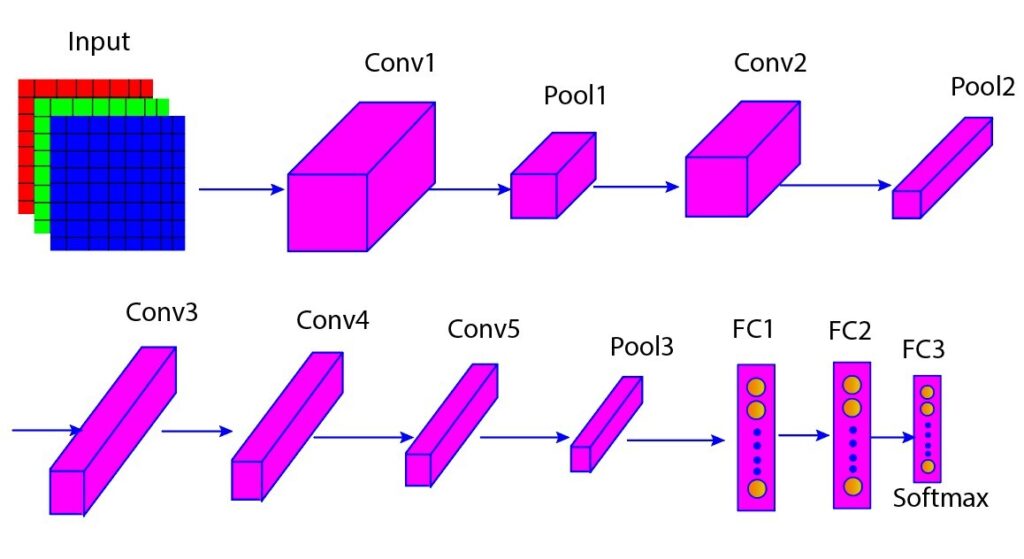
The figure below shows the various layers of the AlexNet architecture (Figure 1). In Table 1, we further listed filter size, number of filters, stride, padding, output size, and activation for each layer. We will discuss these layers in the section below.
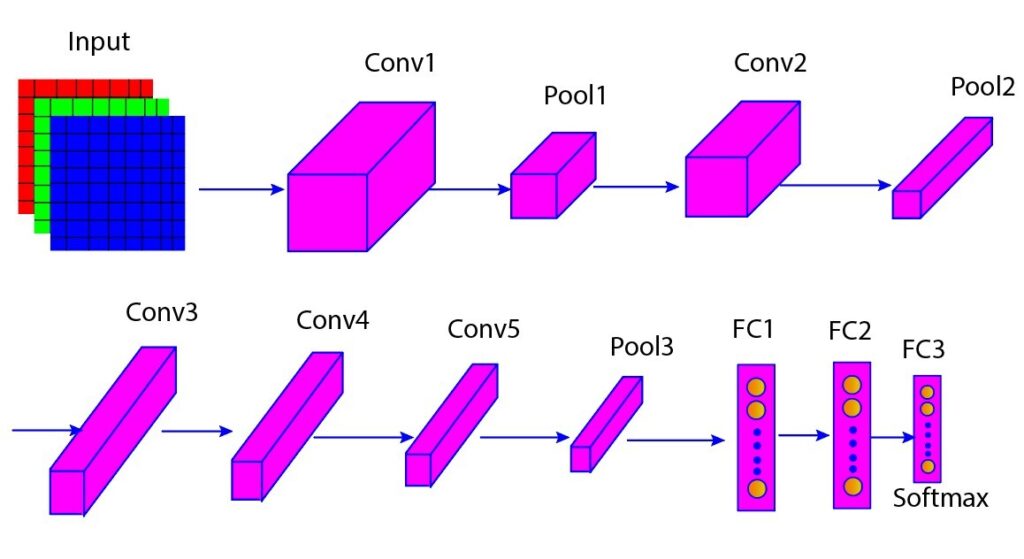
Figure 1: Various layers of AlexNet architecture
Table 1: Layer-wise details of AlexNet architecture
| Layer | Type | Filter Size | Number of Filters | Stride | Padding | Output Size (WxHxD) | Activation |
|---|---|---|---|---|---|---|---|
| Input | - | - | - | - | - | 227x227x3 | - |
| Conv1 | Conv | 11x11 | 96 | 4 | Valid | 55x55x96 | ReLU |
| Pool1 | Max Pooling | 3x3 | - | 2 | 0 | 27x27x96 | - |
| Norm1 | LRN | - | - | - | - | 27x27x96 | - |
| Conv2 | Conv | 5x5 | 256 | 1 | 2 | 27x27x256 | ReLU |
| Pool2 | Max Pooling | 3x3 | - | 2 | 0 | 13x13x256 | - |
| Norm2 | LRN | - | - | - | - | 13x13x256 | - |
| Conv3 | Conv | 3x3 | 384 | 1 | 1 | 13x13x384 | ReLU |
| Conv4 | Conv | 3x3 | 384 | 1 | 1 | 13x13x384 | ReLU |
| Conv5 | Conv | 3x3 | 256 | 1 | 1 | 13x13x256 | ReLU |
| Pool3 | Max Pooling | 3x3 | - | 2 | 0 | 6x6x256 | - |
| FC1 | Fully Connected | - | - | - | - | 4096 | ReLU |
| FC2 | Fully Connected | - | - | - | - | 4096 | ReLU |
| FC3 | Fully Connected | - | - | - | - | 1000 | - |
| Softmax | Softmax | - | - | - | - | 1000 | Softmax |
Convolutional Layers (Conv1-Conv5)
There are five convolutional layers in the AlexNet architecture. These layers apply filters that slide across the images to detect features. The first convolutional layer uses a filter of size 11×11 to capture broader, low-level features like edges and textures. The filter size in the subsequent convolutional layers is less (5×5 or 3×3) as they focus on specific details within prominent features.
Pooling Layers (Pool1-Pool3)
The Max pooling layer helps to reduce the spatial dimensions of the data while retaining important features. There are three max-pooling layers in the AlexNet, which have a filter of size 3×3 with a stride of 2.
Normalization Layer (Norm1 & Norm2)
In the AlexNet architecture, two local response normalization layers (LRN) are used after the first and second convolutional layers to normalize the outputs. It helps the AlexNet network to learn better and differentiate between essential features in the image while avoiding less relevant activations.
Fully Connected Layers (FC1 – FC3)
There are three fully connected dense layers in the AlexNet network, and they are responsible for learning high-level features from the output of the previous convolutional and max-pooling layers. The first two dense layers have 4096 neurons each, while the third dense layer has 1000 neurons corresponding to the 1000 classes in the ImageNet dataset.
Important Features Of AlexNet Architecture
Some of the important features of AlexNet architecture that made it successful are:
Rectified Linear Unit Activation Function (ReLU)
Before the development of AlexNet architecture, deep convolutional neural networks faced a significant challenge known as the vanishing gradient problem due to the use of sigmoid and tanh functions. These functions tend to saturate at positive or negative values, leading to gradients approaching zero during backpropagation.
AlexNet network significantly mitigated the impact of the vanishing gradient problem by using the ReLU activation function. The ReLU activation function is non-saturating, allowing gradients to flow freely through the network. This nature of ReLU makes the deep CNNs computationally faster and more accurate while overcoming the vanishing gradient problem.
We want to mention that the ReLU does not eliminate the vanishing gradient problem completely. We often need other techniques in conjunction with ReLU to develop efficient and accurate deep-learning models while avoiding vanishing gradient problems.
Max pooling
AlexNet network uses max pooling to reduce the size and complexity of feature maps generated by the convolutional layers. It performs max operations on small regions of the feature map, such as 2×2 or 3×3, and outputs the maximum value. This approach helps to preserve the essential features while discarding the redundant or noisy features.
From the figure of the AlexNet architecture above, we observe that there are max pooling layers after the first, second, and fifth convolutional layers. These max pooling layers have overlapping regions in the feature map, which are pooled together. This helps to retain more essential information and reduce error rates compared to non-overlapping max pooling.
Data Augmentation
Training deep convolutional networks with a limited dataset can be challenging due to overfitting. To overcome this, AlexNet used the data augmentation approach to increase the size of the training dataset artificially. Data augmentation creates new images by randomly altering the original images. Alterations include cropping, flipping, rotating, adding noise, and changing the colors of the original images.
The data augmentation approach significantly increases the size and quality of the training dataset in the AlexNet model, leading to increased generalization, improved training speed and accuracy, and addressing overfitting.
Dropout
Dropout is a regularization method in neural networks to avoid overfitting. It randomly deactivates some neurons in each layer during the training process.
Dropout forces neural networks to rely on different neuron combinations in each iteration, discouraging reliance on specific features in the training data. Consequently, it helps avoid overfitting and increases the generalization ability of the model.
In the AlexNet architecture, the dropout is applied in the first two fully connected layers. Both the dense layers are susceptible to overfitting as they use very high numbers of neurons (4096 each).
A dropout rate of 50% is used in the AlexNet, which means that half of the neurons in each layer are randomly dropped out during training. This high rate highlights the importance of preventing overfitting in these large layers.
Applications Of AlexNet
-
Image Classification: AlexNet can be used to identify and categorize objects in images, such as animals, plants, vehicles, etc.
-
Object Detection: We can use AlexNet to detect and identify various objects in an image, such as faces, pedestrians, and cars.
-
Face recognition: With the help of Alexnet, we can recognize and differentiate facial features of humans, such as identity, expression, age, and gender.
-
Scene understanding: AlexNet can be used to analyze images and interpret context and semantics from them, such as indoor/outdoor, day/night, and weather.
-
Image Generation: By using AlexNet, we can also generate realistic images, such as faces, landscapes, and artwork from text descriptions, sketches, or other images.
Conclusion
AlexNet is a type of convolutional neural network that won the ImageNet challenge in 2012 and sparked a revolution in the field of deep learning and computer vision.
The design of AlexNet architecture consists of eight layers with learnable parameters. It introduced several novel techniques, such as ReLU activation, dropout, data augmentation, and GPU parallelism.
AlexNet network demonstrated that deep CNNs can achieve great results on large-scale image recognition tasks using purely supervised learning. It set a new standard for CNN models and inspired many subsequent research works in the field of deep learning and computer vision.
References
Introduction To AlexNet Architecture
Frequently Asked Questions (FAQs)
What is AlexNet architecture in CNN?
AlexNet is a pioneering convolutional neural network (CNN) designed by Alex Krizhevsky and his colleagues in 2012 for image recognition and classification tasks. It won first place in the ImageNet Large-Scale Visual Recognition Challenge with a top-5 error rate of 15.3%, outperforming the runners-up by a big margin. AlexNet is an important milestone in deep learning, and it showed the world that by using deeper and larger neural networks, we can solve real-world problems.
Why is AlexNet better than CNN?
AlexNet is a specific type of Convolutional Neural Network (CNN) that has shown great performance in image recognition tasks. The success of AlexNet can be attributed to its deep architecture, the use of the rectified linear unit (ReLU) activation function, data augmentation, normalization, and the implementation of the dropout layer. However, it is worth noting that the AlexNet is not inherently better than other CNNs. Instead, it is a specific type of CNN that helped to popularize the use of CNNs for image-related tasks.
What are the key features of AlexNet architecture?
The key features of the AlexNet architecture include:
-
ReLU Activation Function: AlexNet uses the ReLU activation function to mitigate the vanishing gradient problem, improving the accuracy as well as the computational performance of the model.
-
Max Pooling: AlexNet uses max pooling to reduce the size and complexity of the feature maps generated by the convolutional layers while preserving important features.
-
Data Augmentation: Alexnet uses data augmentation to artificially increase the size and quality of the training dataset, which helps to address overfitting and improve the generalization ability of the model.
-
Dropout: AlexNet uses dropout during training, which helps to avoid overfitting by randomly deactivating neurons in each layer.
