

Overview
Named entity recognition in NLP is used to detect and categorize essential information from unstructured text. We can call the essential information as named entities, including person names, organization names, locations, medical codes, time, quantities, monetary values, etc. Named entity recognition (NER) plays a vital role in various industries by automating information retrieval of unstructured text data. For example, Apple’s Siri and Amazon’s Alexa use NER to comprehend and reply to user commands accurately and efficiently. In this article, we will explore named entity recognition in NLP with the help of practical applications using Python.
Essential Libraries For Named Entity Recognition In NLP
We can use various open-source libraries for named entity recognition in NLP. Let us briefly discuss them one by one:
- Standford NER: Standford NER is a Java-based library for named entity recognition. It was developed by the NLP research group of Standford University. It offers pre-trained models in various languages for NER.
- AllenNLP: AllenNLP is a popular Python-based library for named entity recognition in NLP. However, the AllenNLP may require more manual configuration and setup than Spacy.
- NLTK: NLTK is a Python-based library that provides tools for various NLP tasks, such as named entity recognition (NER). It uses rule-based methods depending on regular expressions and provides a predefined set of named entities for NER tasks.
- Spacy: Spacy is a popular Python-based library for named entity recognition (NER). The NER component of Spacy uses a transition-based neural network to identify and classify entities. We can use pre-trained models provided by Spacy or train an NER model with the custom dataset for NER tasks.
The libraries discussed above use different approaches for named entity recognition in NLP. Among them, Spacy is the most popular for named entity recognition in NLP, as it is easy to use and offers production-grade performance.
Why use Named Entity Recognition (NER)?
There are diverse applications of named entity recognition in various sectors, such as finance, customer support, resume evaluation, space exploration, education, public health, cyber securities, and environmental science. For example, HR departments may use NER to evaluate resumes by extracting important information for the candidates, such as skills and experience. In cybersecurity, NER may be used to identify and classify cybersecurity entities, thus improving threat detection. Therefore, name entity recognition in NLP is valuable for extracting essential information from unstructured data.
Named Entity Recognition using the Pertained model of Spacy
Spacy is an open-source library with several pre-trained models for natural language processing. We can use pre-trained Spacy models for named entity recognition. The table below shows various named entities for the pre-trained model of Spacy.
| Entity Type | Description |
|---|---|
| PERSON | People, including fictional. |
| NORP | Nationalities or religious or political groups. |
| FAC | Buildings, airports, highways, bridges, etc. |
| ORG | Companies, agencies, institutions, etc. |
| GPE | Countries, cities, states. |
| LOC | Non-GPE locations, mountain ranges, bodies of water. |
| PRODUCT | Objects, vehicles, foods, etc. |
| EVENT | Named hurricanes, battles, wars, sports events, etc. |
| WORK_OF_ART | Titles of books, songs, etc. |
| LAW | Named documents made into laws. |
| LANGUAGE | Any named language. |
| DATE | Absolute or relative dates or periods. |
| TIME | Times smaller than a day. |
| PERCENT | Percentage, including "%" |
| MONEY | Monetary values, including unit. |
| QUANTITY | Measurements, as of weight or distance. |
| ORDINAL | "first", "second", etc. |
| CARDINAL | Numerals that do not fall under another type. |
There are various types of pre-trained models:
- en_core_web_sm: The en_core_web_sm is a small model that includes vocabulary, syntax, and entities. This model is suitable when you have memory constraints. We can use the model as a starting point for the NER task.
- en_core_web_md: The en_core_web_md is a medium-sized model that includes vocabulary, syntax, entities, and word vectors. The model is suitable for a wide range of NLP tasks and is more accurate than en_core_web_sm.
- en_core_web_lg: The en_core_web_lg is suitable when the priority is accuracy. The model includes vocabulary, syntax, entities, and word vectors, making it ideal for demanding NLP tasks.
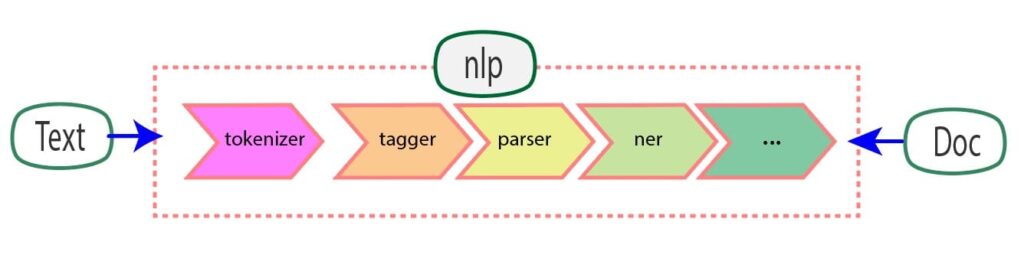
NLP pipeline in SpaCy
The SpaCy pipeline is a robust framework for named entity recognition in NLP. It is a sequence of components or pipes for processing and transforming data. A typical NLP pipeline of Spacy includes several built-in components, such as a tokenizer, tagger, lemmatizer, parser, and entity recognizer. We can speed up NER while turning off unnecessary components such as tagger and parser.
How to implement the NER model in Python
The section below describes implementing the NER model in Python using SpaCy. You can also access the code in the link.
Install Spacy
Let us install SpaCy using pip.
!pip install spacy
Let us download the medium sized English model for SpaCy using the following command.
!python -m spacy download en_core_web_md
Import Spacy And Load Language Model
import spacy
nlp = spacy.load("en_core_web_md")
Process Text Using Language Model
Here, we will process a sample text using language model (en_core_web_md), which tokenizes the text first and then identifies various elements from the text such as named entities, part-of-speech tags, and dependencies.
text = "Apple is looking at buying U.K. startup for $1 billion. The Indian Space Research Organisation, headquartered in Bengaluru, is the national space agency of India. It operates under the Department of Space, which is directly overseen by the Prime Minister of India. The company XYZ is known for its innovative technology in the field of artificial intelligence. John Doe, an expert in machine learning, joined ABC Corporation last month. The United Nations is an international organization founded in 1945. It is currently made up of 193 Member States."
doc = nlp(text)
Extract Named Entities
The code below iterates through the named entities identified in the previous steps and prints each entity along with its entity label.
for ent in doc.ents:
print(ent.text, ent.label_)
Output:
[('Apple', 'ORG'), ('U.K.', 'GPE'), ('$1 billion', 'MONEY'), ('The Indian Space Research Organisation', 'ORG'), ('Bengaluru', 'GPE'), ('India', 'GPE'), ('the Department of Space', 'ORG'), ('India', 'GPE'), ('XYZ', 'ORG'), ('John Doe', 'PERSON'), ('ABC Corporation', 'ORG'), ('last month', 'DATE'), ('The United Nations', 'ORG'), ('1945', 'DATE'), ('193', 'CARDINAL')]
Visualize Named Entities Using displaCy
The named entities can also be visualized using a visualization tool called displacy. With the help of displacy, we can visualize the named entities in a more interactive manner, thus making it easier to understand the result.
from spacy import displacy
doc = nlp(text)
spacy.displacy.render(doc, style="ent", jupyter=True)

Store The Named Entities In Tabular Format
We can further store the data in a tabular format using Pandas’ data frame using the code below.
import pandas as pd
entities = [(ent.text, ent.label_) for ent in doc.ents]
df = pd.DataFrame(entities, columns=["Entity", "Label"])
Output:
Entity Label
0 Apple ORG
1 U.K. GPE
2 $1 billion MONEY
3 The Indian Space Research Organisation ORG
4 Bengaluru GPE
5 India GPE
6 the Department of Space ORG
7 India GPE
8 XYZ ORG
9 John Doe PERSON
10 ABC Corporation ORG
11 last month DATE
12 The United Nations ORG
13 1945 DATE
14 193 CARDINAL
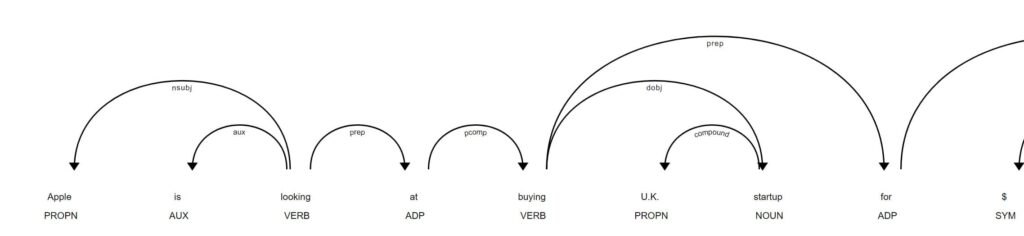
Visualize The Dependency Parse
We can further visualize the dependency parse of the text by using the displacy.render() function with the dependency parameter.
doc = nlp(str(text))
displacy.render(doc, style='dep',jupyter=True)
Limitations of the Pre-trained NER Model
- The pre-trained models may perform poorly on domain-specific text data (such as financial or medical data) as they are trained on general text data.
- It is not possible to customize pre-trained models to recognize new entities or to improve the performance of recognizing existing entities.
- The accuracy of the pre-trained model may not be sufficient for many real-world cases, which may lead to incorrect entity recognition.
Conclusion
In this article, we have learned how to apply a pre-trained Spacy model for identifying and recognizing named entities from sample text data. We found that the named entity recognition component of Spacy can successfully identify and classify entities, such as people, organizations, locations, and dates from the text data.
However, the pre-trained spacy model has several limitations, such as limited accuracy for specific use cases, limited domain-specific knowledge, and lack of customization options for identifying new entities. However, we can develop custom models for named entity recognition in NLP that may ensure better accuracy and domain-specific relevance.
Frequently Asked Questions
What is the purpose of NER?
With the help of NER, we can automatically extract structured information from unstructured text. It enables machines to identify and categorize entities in a meaningful manner. This is beneficial for various applications including text summarization, building knowledge graphs, question answering, and constructing knowledge graphs.
What is an example of a named entity?
Examples of named entities include personal names (first and last names), geographic locations, ages, addresses, phone numbers, and company names. These entities are crucial for tasks such as information extraction and natural language processing.
What is the ML NER model?
A Named Entity Recognition (NER) in NLP helps to identify and classify named entities in text. These models are trained on annotated datasets and use algorithms such as conditional random fields (CRFs), recurrent neural networks (RNNs), or transformer-based architectures to recognize and categorize entities. This helps in various tasks such as information extraction, text summarization, and question answering.
How does named entity recognition work?
Named Entity Recognition in NLP helps to identify and categorize entities within a text into predefined categories. There are several step-in name entity recognition models such as preprocessing the text, extracting relevant features, and utilizing a machine learning model to identify and categorize entities such as names, locations, and dates. Models like conditional random fields, recurrent neural networks, or transformer-based architectures are frequently employed for this task.
References

Dr. Partha Majumder is a distinguished researcher specializing in deep learning, artificial intelligence, and AI-driven groundwater modeling. With a prolific track record, his work has been featured in numerous prestigious international journals and conferences. Detailed information about his research can be found on his ResearchGate profile. In addition to his academic achievements, Dr. Majumder is the founder of Paravision Lab, a pioneering startup at the forefront of AI innovation.
Good article. Really loved reading it.
Thank you for appreciating our article.
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.
Thank you for your sharing. I am worried that I lack creative ideas. It is your article that makes me full of hope. Thank you. But, I have a question, can you help me?
Your article helped me a lot, is there any more related content? Thanks!
Your point of view caught my eye and was very interesting. Thanks. I have a question for you.